AI News for 7/1/2024-7/2/2024. We checked 7 subreddits, 384 Twitters and 30 Discords (419 channels, and 2518 messages) for you. Estimated reading time saved (at 200wpm): 310 minutes. You can now tag @smol_ai for AINews discussions!
Neurosymbolic stans rejoice!
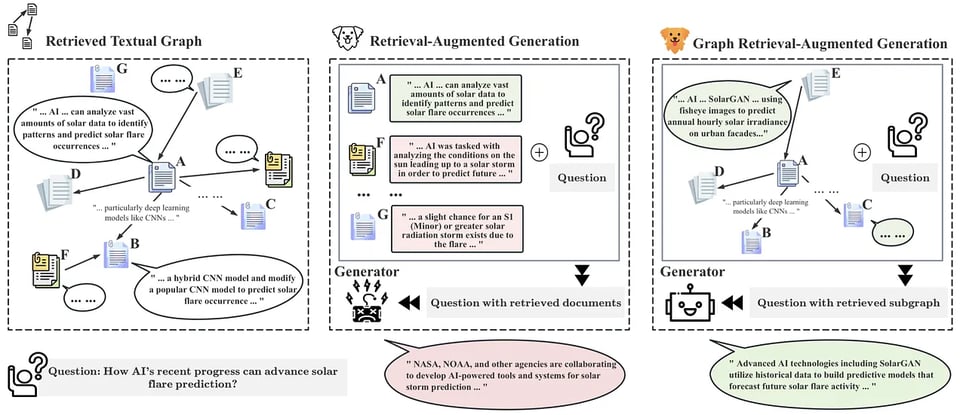

Microsoft Research first announced GraphRAG in April, and it was surprisingly popular during Neo4j's workshops and talks at the AI Engineer World's Fair last week (videos aren't yet live so we haven't seen it yet, but soon (tm)). They have now open sourced their code. As Travis Fischer puts it:
- use LLMs to extract a knowledge graph from your sources
- cluster this graph into communities of related entities at diff levels of detail
- for RAG, map over all communities to create "community answers" and reduce to create a final answer.
Or in their relatively less approachable words:
However, the dirty secret of all performance improvement techniques of this genre: token usage and inference time goes up 🙃
Also of note: their prompt rewriting approach
{% if medium == 'web' %}
Table of Contents
[TOC]
{% else %}
The Table of Contents and Channel Summaries have been moved to the web version of this email: [{{ email.subject }}]({{ email_url }})!
{% endif %}
AI Twitter Recap
all recaps done by Claude 3 Opus, best of 4 runs. We are working on clustering and flow engineering with Haiku.
LLM Model Releases and Improvements
- Gemma 2 models released: @rasbt noted Gemma 2 models explore techniques without increasing dataset sizes, focusing on developing small & efficient LLMs. Key design choices include sliding window attention, group-query attention, and RMS norm. Gemma 2 is almost as good as the 3x larger Llama 3 70B.
- Anthropic's Claude 3.5 Sonnet model: @alexandr_wang reported Claude 3.5 Sonnet is now #1 on Instruction Following and Coding in ScaleAI's hidden evals. However, it loses points on writing style and formatting vs other top models.
- Nvidia's Nemotron 340B model: @osanseviero shared that Nemotron, a 340B parameter model, was released as part of the June open model releases.
- Qwen2-72B tops HuggingFace Open LLM Leaderboard: @rohanpaul_ai noted Qwen2-72B scores 43.02 on average, excelling in math, long-range reasoning, and knowledge. Interestingly, Llama-3-70B-Instruct loses 15 points to its pretrained version on GPQA.
Retrieval Augmented Generation (RAG) Techniques and Challenges
- RAG Basics Talk: @HamelHusain shared a talk on RAG Basics from the LLM conf, covering key concepts and techniques.
- Limitations of RAG: @svpino discussed the limitations of RAG, including challenges with retrieval, long context windows, evaluation, and configuring systems to provide sources for answers.
- Improving LLM Context Usage in RAG: @AAAzzam shared a tip to get LLMs to use context more effectively - LLMs use info from function calls far more than general context. Transforming context into pseudo function calls can improve results.
Synthetic Data Generation and Usage
- Persona-Driven Data Synthesis: @omarsar0 shared a paper proposing a persona-driven data synthesis methodology to generate diverse synthetic data. It introduces 1 billion diverse personas to facilitate creating data covering a wide range of perspectives. A fine-tuned model on 1.07M synthesized math problems achieves 64.9% on MATH, matching GPT-4 performance at 7B scale.
- AutoMathText Dataset: @rohanpaul_ai highlighted the 200GB AutoMathText dataset of mathematical text and code for pretraining mathematical language models. The dataset consists of content from arXiv, OpenWebMath, and programming repositories/sites.
- Synthetic Data for Math Capabilities: @rohanpaul_ai noted a paper showing synthetic data is nearly as effective as real data for improving math capabilities in LLMs. LLaMA-2 7B models trained on synthetic data surpass previous models by 14-20% on GSM8K and MATH benchmarks.
Miscellaneous
- 8-bit Optimizers via Block-wise Quantization: @rohanpaul_ai revisited a 2022 paper on 8-bit optimizers that maintain 32-bit optimizer performance. Key innovations include block-wise quantization, dynamic quantization, and stable embedding layers to reduce memory footprint without compromising efficiency.
- Understanding and Mitigating Language Confusion: @seb_ruder introduced a paper analyzing LLMs' failure to generate text in the user's desired language. The Language Confusion Benchmark measures this across 15 languages. Even strong LLMs exhibit confusion, with English-centric instruction tuning having a negative effect. Mitigation measures at inference and training time are proposed.
- Pricing Comparison for Hosted LLMs: @_philschmid shared an updated pricing sheet for hosted LLMs from various providers. Key insights: ~$15 per 1M output tokens from top closed LLMs, Deepseek v2 cheapest at $0.28/M, Gemini 1.5 Flash best cost-performance, Llama 3 70B ~$1 per 1M tokens.
AI Reddit Recap
Across r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity. Comment crawling works now but has lots to improve!
LLM Development and Capabilities
- Gemma 2 27B model issues: In /r/LocalLLaMA, users are questioning if the Gemma 2 27B model is broken with recent llamacpp updates. Comparisons show answers are similar to aistudio.google.com.
- Scaling synthetic data creation: New research discussed in /r/singularity leverages a collection of 1 billion diverse personas to create synthetic data at scale for training LLMs, enabling tapping into many perspectives for versatile data synthesis.
- LLMs more linear than thought: In /r/MachineLearning, new research reveals near-perfect linear relationships in transformer decoders. Removing or approximating linear blocks doesn't significantly impact performance, challenging assumptions about transformer architectures.
Stable Diffusion Models and Training
- Vanilla SD 2.1 for hyper-realistic faces: In /r/StableDiffusion, the vanilla SD 2.1 base model is being used with extensions like Scramble Prompts and Mann-E_Dreams-0.0.4 in Forge UI to generate impressive hyper-realistic face editing results.
- Halcyon 1.7 tops SDXL rankings: Halcyon 1.7 takes the top spot in SDXL model rankings for prompt adherence and rich results, according to comparisons in /r/StableDiffusion.
- Maintaining facial consistency with IC-light: In /r/StableDiffusion, a user is seeking tips for keeping faces consistent across frames and lighting conditions when using IC-light in projects, looking for techniques, settings and tools to achieve stability.
Hardware and Performance
- Watercooling RTX 3090s: In /r/LocalLLaMA, a user is seeking advice on watercooling a 4x 3090 rig for space efficiency, asking if a single loop is viable to prevent throttling.
- Multiple GPUs for inference speed: Another /r/LocalLLaMA post questions if adding another GPU will actually increase inference speed for llama.cpp via Ollama or just provide a larger memory pool, seeking clarification before purchase.
- Deepspeed vs Unsloth for multi-GPU: An /r/LocalLLaMA thread compares the effectiveness of Deepspeed without Unsloth vs Unsloth with data parallelism for multi-GPU training, planning to use stage 2 Deepspeed if it makes a difference.
Optimizations and Benchmarks
- Beating NumPy matrix multiplication: In /r/LocalLLaMA, a user shares a highly optimized C implementation of matrix multiplication following BLIS design that outperforms NumPy/OpenBLAS with just 3 lines of OpenMP for parallelization.
- Gemma 2 usage with Hugging Face: A Twitter thread linked in /r/LocalLLaMA covers proper Gemma 2 usage with Hugging Face Transformers, including bug fixes, soft capping logits, and precision settings for best results.
- Anthropic funding third-party benchmarks: Anthropic announces an initiative to fund the development of third-party benchmarks for evaluating AI models.
AI Discord Recap
A summary of Summaries of Summaries
-
LLM Performance and Benchmarking Advancements:
-
New models like Phi-3 Mini from Microsoft and Gemma 2 from Google are showing significant improvements in instruction following and performance.
-
The AI community is actively discussing and comparing model performances, with debates around benchmarks like AlignBench and MT-Bench.
-
There's growing interest in reproducible benchmarks, with efforts to replicate results using tools like
lm_evalfor models such as Gemma 2.
-
-
Optimizing LLM Training and Inference:
-
Discussions across discords highlight the importance of efficient training techniques, with focus on methods like eager attention for Gemma2 models.
-
The community is exploring various quantization techniques, such as those implemented in vLLM and llama.cpp, to improve inference performance.
-
Hardware considerations for AI tasks are a hot topic, with debates around GPU vs CPU performance and the potential of specialized hardware like Apple's variable bit quantization.
-
-
Open-Source AI Development and Community Collaboration:
-
Projects like Axolotl and LlamaIndex are fostering community-driven development of AI tools and frameworks.
-
There's increasing interest in open-source alternatives to proprietary models, such as StoryDiffusion as an alternative to Sora.
-
Collaborative efforts are emerging around projects like OpenDevin and Microsoft's Graph RAG Architecture.
-
-
Multimodal AI and Generative Modeling:
-
Advancements in vision-language models are being discussed, with projects like Vistral 7B for Vietnamese and Florence-2 running locally with WebGPU.
-
Text-to-video generation is gaining traction, with tools like Runway's Gen-3 sparking discussions about capabilities and pricing.
-
The community is exploring combinations of models and techniques to achieve DALLE-3-level outputs, indicating a trend towards more sophisticated multimodal systems.
-
PART 1: High level Discord summaries
LM Studio Discord
- LM Studio's Shiny New Armor: The LM Studio 0.2.27 release celebrated improvements for Gemma 9B and 27B models, with users prompted to download new versions or embrace the auto-update feature. Posted release notes reveal bug fixes and an updated
llama.cppcommit ID.- Community members also eagerly discussed the Phi-3 Mini jump to Phi 3.1 by Microsoft, emphasizing the leap in performance and instruction adherence - head over to Hugging Face to catch the wave.
- Heatwaves and Hurdles in Hardware: VRAM's supremacy over RAM for LLM tasks was the hot topic, with consensus leaning towards 8GB VRAM as the recommended minimum for avoiding performance pitfalls. A user's rig, boasting a total of 120GB VRam with 5x water-cooled 4090s, sparked interest for its brute force approach to LLM inference.
- However, not all sailed smoothly as members reported GPU idling temperature issues with LM Studio on hardware like a P40 GPU, along with compatibility concerns particularly with AMD GPUs post update, as seen in Extension-Pack-Instructions.md.
- Collaborative Debugging in Dev Chat: A clash of SDK versions in LM Studio led users down a rabbit hole of
await client.llm.load(modelPath);errors after upgrading to 0.2.26. The lmstudio.js GitHub issue hosted the saga, setting the stage for community troubleshooting.- Discord bots weren't immune to challenges either; a case of TokenInvalid error, pinned on the lack of MessageContent intents, was laid to rest through community collaboration, highlighting the spirit of collective problem-solving.
- Quantization Quintessentials and Gemma 2: Enthusiasm for the Gemma 2 model updates matched stride with the Phi 3.1 enhancements, both promising smoother operation with the latest LM Studio iteration. The community's pivot towards quantized versions, like Gemma 2 9b and 27b, indicates a keen eye on performance optimizations.
- With Gemma 2 facing an unexpected setback on an AMD 6900 XT GPU, as revealed by the 'failed to load model' debacle, the tides seem to favor a 're-download and try again' approach, albeit with members staying on standby for a more solid fix.
HuggingFace Discord
- Transformers' Tech Triumphs: With the Transformers 4.42 release, users are now able to access a variety of fresh models and features, including Gemma 2, RT-DETR, and others, highlighted in the release notes.
- Community reactions show elevated excitement for this update, anticipating enhanced capabilities and efficient RAG support, as expressed in enthusiastic responses.
- Chronos Data Chronicles: AWS has launched its Chronos datasets on Hugging Face, along with evaluation scripts, providing datasets used for both pretraining and evaluation as detailed here.
- This dissemination of datasets is recognized with community acclaim, marked as a significant contribution for those interested in temporal data processing and analysis.
- Metrics at Scale: Hub's Major Milestone: 100k public models are leveraging the Hub to store
tensorboardlogs, facilities summarized here, illustrating the expanding utility of the platform.- This accomplishment is considered a major nexus for model monitoring, streamlining the process of tracking training logs alongside model checkpoints.
- Vietnamese Vision-Language Ventures: A new wave in Vietnamese AI is led by Vistral 7B, a Vision-Language model, based on LLaVA and Gemini API to enhance image description capacities as shown on their GitHub.
- The team has opened avenues for community engagement, seeking insights into model performance through an interactive demo, harnessing further vision capabilities.
- AI Finesse in Fashion: E-commerce's Future: Tony Assi showcased a variety of AI-driven projects tailored for e-commerce, with a special focus on using computational vision and machine learning to innovate in fashion.
- The diversity of these applications, available here, underlines the potential AI holds in transforming the e-commerce industry.
CUDA MODE Discord
- CUDA Conclave Crunch: A CUDA-only hackathon will surge in San Francisco on July 13th, hosted by Chris Lattner with H100 access, a testament to Nebius AI's backing.
- Aiming to foster a hardcore hacker mindset, the event persists from 12:00pm to 10:00pm, flaunting strict CUDA adherence and sparking discussion threads on Twitter.
- Matrix Multiplication Mastery: Mobicham released a matrix multiplication guide, demonstrating calculations on CPUs, a stand-out resource for AI engineers focusing on foundational operations.
- This often under-discussed core of AI model efficiency gets a spotlight, paving the way for discussions around compute optimization in AI workflows.
- INTx's Benchmarking Blitz: INTx performance benchmarking soars past fp16, with int2 and int4 breaking records in tokens per second.
- The torchao quantization experiments reveal that int8-weight and intx-4 demonstrate formidable speed, while evaluations optimized at batch size 1 underscore future performance explorations.
- Benchmark Script Bazaar: MobiusML shared benchmark scripts vital for the AI community, alongside token/second measurement methodologies.
- These benchmarks are crucial for performance metrics, especially after resolving recent issues with transformers and their caching logic.
- CUDA Chores to Core Overhaul: Engineers revitalize helper and kernel functions within CUDA MODE, enhancing efficiency and memory optimization, while championing GenericVector applications.
- AI practitioners scrutinize training stability, dissect dataset implications, simplify setups, and discuss inference optimization, as evident in contributions to repositories like llm.c.
Perplexity AI Discord
- Talk the Talk with Perplexity's Android App: Perplexity AI released a voice-to-voice feature for Android, enabling a seamless hands-free interaction and soliciting user feedback via a designated channel. The app offers both Hands-free and Push-to-talk modes.
- The Pro Search update magnifies Perplexity's prowess in handling complex queries with staunch support for multi-step reasoning, Wolfram|Alpha, and code execution. Explore the enhancements here.
- Curating Knowledge with Perplexity AI: User discussions surfaced regarding Perplexity AI's search engine limitations, like bias toward Indian news and erratic source selection, assessing the tools against peers like Morphic.sh. The need for source-setting enhancements and balanced global content is evident.
- Community conversations expose a bottleneck with Claude's 32k tokens in Perplexity AI, dampening user expectations of the advertised 200k tokens. This marks a departure from an ideal AI assistant towards a more search-centric model.
- Perplexity's Plotting Potential Probed: Queries on visualizing data within Perplexity AI concluded that while it doesn't inherently generate graphs, it aids in creating code for external platforms like Google Colab. Members proposed utilizing extensions like AIlin for integrated graphical outputs.
- Citing the proliferation of referral links, the Perplexity AI userbase anticipates a potential trial version, despite the apparent absence due to misuse in the past. The community's thirst for firsthand experience before subscription remains unquenched.
- Puzzle Phenom's Anniversary to Meta's Meltdown: Marking half a century of cognitive challenge, the Rubik's Cube celebrates its 50th anniversary with a special tribute, available here. An eclectic array of news shadows the cube's glory, from Meta's EU charges to electric flight innovation.
- Discussions around business plan creation via Perplexity AI surfaced, revealing a lean canvas tutorial to structure entrepreneurial strategy. Eager business minds are drawn to the guide, found here.
- API Angst and Anticipation in Perplexity's Pipeline: The API ecosystem in Perplexity AI faced a hiccup with Chrome settings failing to load, prompting users to explore Safari as an alternative, with the community suggesting cache clearance for remediation.
- While Sonnet 3.5 remains outside the grasp of the Perplexity API, the interest in wielding the search engine via API kindled discussions about available models and their functional parity with Hugging Face implementations. Detailed model documentation is referenced here.
Unsloth AI (Daniel Han) Discord
- Billion-Persona Breakthrough Tackles MATH: Aran Komatsuzaki detailed the Persona Hub project that generated data from 1 billion personas, improving MATH scores from 49.6 to 64.9. They shared the concept in a GitHub repo and an arXiv paper, sparking conversations on data value over code.
- Discussions pivoted on the ease of replicating the Persona Hub and the potential for scaling synthetic data creation, with a member emphasizing, 'the data is way more important than the code'.
- Phi-3 Mini Gets Performance-Enhancing Updates: Microsoft announced upgrades to Phi-3 Mini, enhancing both the 4K and 128K context model checkpoints as seen on Hugging Face and sparking speculations of advanced undisclosed training methods.
- Community reactions on the LocalLLaMA subreddit were enthusiastic, leading to humorous comparisons with OpenAI's secretive practices, as someone quipped 'ClosedAI’s CriticGPT'.
- Unsloth Embraces SPPO for Streamlined Integration: theyruinedelise confirmed SPPO's compatibility with Unsloth, discussing how it operates alongside TRL, offering a straightforward integration for Usloth users.
- Excitement on the integration front continues as Unsloth reliably extends support to SPPO through TRL, simplifying workflows for developers.
- Chit-Chat with Chatbots in Discord: The llmcord.py script by jakobdylanc, available on GitHub, repurposes Discord as an LLM interface, earning acclaim from the community for its practicality and ease of use.
- Community members, inspired by the release, shared their compliments, with expressions like, 'Nice great job!' emphasizing collective support for the innovation.
- A Collective Call for Notebook Feedback: A new Colab notebook supporting multiple datasets appealed to the community for feedback, aiming to refine user experience and functionality.
- The notebook's noteworthy features, like Exllama2 quant support and LoRA rank scaling, mirror the community's collaborative ethos, with anticipation for constructive feedback.
Stability.ai (Stable Diffusion) Discord
- VRAM Vanquishing Diffusion Dilemmas: A member queried about using Stable Diffusion with only 12GB VRAM, facing issues since everydream2 trainer requires 16GB. Another shared successfully generating a tiny checkpoint on an 8GB VRAM system after a 4-hour crunch.
- The conversation shifted to strategies for running Stable Diffusion on systems with VRAM constraints, with members swapping tips on different models and setups that could be more accommodating of the hardware limitations.
- Stable Diffusion 3 Struggles: The community dissected the weaknesses of Stable Diffusion 3 (SD3), citing missing its mark on finer tunability and incomplete feature implementations, like the inefficient training of Low-Rank Adaptation (LoRA).
- One participant voiced their frustration about SD3's image quality deficits in complex poses, advocating for further feature advancements to overcome areas where the model's performance stutters.
- LoRA's Learning Loop: Discussions spiked over training LoRA (Low-Rank Adaptation) for niche styles, ranging from 3D fractals to game screencaps, though Stable Diffusion 3's restrictive nature with LoRA training was a constraint.
- Community members enthusiastically exchanged workarounds and tools to aid specialized training, iterating the value of trial and error in the quest for custom model mastery.
- Stylistic Spectrum of Stable Diffusion: Participants shared their triumphs and trials with Stable Diffusion across a wide stylistic spectrum, from the sharpness of line art to the eeriness of horror, each with a tale of use-case victories and prompt-gone-wild unpredictability.
- Members delighted in the model's capability to interweave accountabilities from different visual narratives, despite the inexplicable mix-ups that prompts can sometimes bestow.
- Art vs. AI: The Anti-AI Algorithm Quandary: The guild debated the creation of software to shield artist creations from AI incorporation, referencing tools like Glaze and Nightshade, acknowledging the approach's shortcomings against persistent loophiles.
- The debate unraveled the practicality of embedding anti-AI features into artworks and discussed the moral questions tied to the reproduction of digital art, punctuated by the challenge of effectively safeguarding against AI assimilation.
OpenAI Discord
- Sticker Shock & Silicon Block: Engineering circles buzzed about the prohibitive cost of 8 H100 GPUs, with figures quoted at over $500k, and bottlenecks in acquisition, requiring an NVIDIA enterprise account.
- A side chat uncovered interest in alternatives such as Google TPUs and services like Paperspace, which provides H100s for $2.24 an hour, as potential cost-effective training solutions.
- AI Artisans Appraise Apparatus: Artificial image aficionados aired grievances about tools like Luma Dream Machine and Runway Gen-3, branding them as overpriced, with $15 yielding a meager 6-7 outputs.
- Enthusiasm dwindled with the perceived lack of progression past the capabilities of predecessors, prompting a demand for more efficiency and creativity in the generative tools market.
- Multi-Step Missteps in Model Prompts: The community contemplated over GPT's tendency to skip steps in multi-step tasks, despite seemingly clear instructions, undermining the model's thoroughness in task execution.
- A technique was shared to structure instructions sequentially, 'this comes before that', prompting GPT to follow through without missing steps in the intended process.
- Intention Interrogation Intrigue: There was a dive into designing a deft RAG-on-GPT-4o prompt for intention checking, segmenting responses as ambiguous, historical, or necessitating new search queries.
- Concerns crept in about the bot's confounding conflation of history with new inquiries, leading to calls for consistency in context and intention interpretation.
- Limitations and Orchestra Layer: Dialogue delved into the limitations of multimodal models and their domain-specific struggles, with specialized tasks like coding in Python as a computed comparison.
- Orchestrators like LangChain leapt into the limelight with their role in stretching AI context limits beyond a 4k token threshold and architecting advanced models like GPT-4 and LLama.
Eleuther Discord
- vLLM Swoops in for HF Rescue: A user suggested vLLM as a solution to a known issue with HF, using a wiki guide to convert models to 16 Bit, improving efficiency.
- The community appreciated the alternative for model deployment, as vLLM proved effective, with users expressing thanks for the tip.
- Gemma 2 Repro Issues Under Microscope: Accuracy benchmarks for Gemma 2 using
lm_evalare not matching official metrics, prompting users to trybfloat16and specific transformer versions as pinpointed here.- The addition of
add_bos_token=trueas amodel_argsyields scores closer to the model's paper benchmarks, notably lambada_openai's accuracy leaping from 0.2663 to 0.7518.
- The addition of
- Semantic Shuffle in LLM Tokenization: A new paper scrutinizes the 'erasure' effect in LLM tokenization, noting how Llama-2-7b sometimes splits words like 'northeastern' into unrelated tokens.
- The research has stirred excitement for its deep dive into high-level representation conversion from random token groups, aiding comprehension of the tokenization process.
- The Factorization Curse Grabs Headlines: Insights from a paper reframing the 'reversal curse' as 'factorization curse' reveal issues in information retrieval with LLMs, introducing WikiReversal to model complex tasks.
- Suggestions hint at UL2 styled objectives after the report implied better model generalization when trained on corrupted or paraphrased data.
- Graphics of Fewshot Prompts Visualized: Users grappling with the impacts of fewshot prompting on accuracy are seeking methods to visualize prompt effects, experimenting with
--log_samplesfor deeper analysis.- A showcased method saves outputs for inspection, aiming to undercover negative fewshot prompting influences and guide improvements in evaluation accuracy.
Nous Research AI Discord
- Apple Dazzles with On-Device Brilliance: Apple's variable bit quantization optimizes on-device LLMs, as exhibited by their Talaria tool which enhanced 3,600+ models since its release. The technique landed a Best Paper Honorable Mention, with credit to notable researchers like Fred Hohman and Chaoqun Wang.
- Further thrust into on-device intelligence was seen at WWDC 2024 with the introduction of Apple Foundation Models that mesh iOS 18, iPadOS 18, and macOS Sequoia, showcasing a 3 billion parameter on-device LLM for daily tasks, according to Apple's report.
- Runway Revolution: Video Gen Costs Stir Stirring Conversations: Runway's state-of-the-art video generation tools, despite the cutting-edge tech, sparked debates over the $12 price tag for a 60-second video.
- Community member Mautonomy led voices that called for a more palatable $0.5 per generation, comparing it to other premium-priced services.
- Genstruct 7B Catalyzes Instruction Creations: NousResearch's Genstruct 7B model emerges as a toolkit for crafting instruction datasets from raw text, romanticizing the inspired beginnings from Ada-Instruct.
- Highlighted by Kainan_e, Genstruct posits to streamline training for LLMs, making it a topic of enchantment for developers seeking to enhance instruction generation capabilities.
- VLLMs: Vision Meets Verbiage in Animation: Discussions ventured into training VLLMs for automating animations, where a diffusion-based keyframe in-betweening method was promoted.
- Community concurred that Hermes Pro might have potential in this space, with Verafice leading criticism for more effective solutions.
Modular (Mojo 🔥) Discord
- Mojo's Raspberry Resolve: An issue surfaced with running Mojo on Ubuntu 24.04 on the Raspberry Pi 5, sparking a search for troubleshooting support.
- This situation remained unresolved in the conversation, highlighting a need for community-driven solutions or further dialogue.
- Mojo Expands its Horizons: Discussions revealed Mojo's potential in advancing areas such as Model and simulator-based RL for LLM agents, along with symbolic reasoning and sub-symbolic model steering.
- Engagement centered on these emerging applications, where community members expressed eagerness to collaborate and exchange insights.
- Benchmark Boons & Blunders: Community efforts yielded significant enhancements to the testing and benchmarking framework in Mojo, notably improving performance metrics.
- Despite this progress, challenges such as benchmark failures due to rounding errors and infinite loops during GFlops/s trials underscore the iterative nature of optimization work.
- Nightly Compiler Complexities: The release of Mojo compiler nightly version 2024.7.205 prompted engagements on version control with
modular update nightly/mojo, accompanied by resolved CI transition issues.- Merchandise inquiries led to direct community support, while some members faced challenges relating to nightly/max package updates that were eventually addressed.
- Matrix Multiplication Musings: A flurry of activity centered on
src/maincompilation errors, specificallyDTypePointerinmatrix.mojo, leading to suggestions of stable build usage.- Participants brainstormed improvements to matrix multiplication, proposing vectors such as vectorization, tiling, and integrating algorithms like Strassen and Winograd-Copper.
OpenRouter (Alex Atallah) Discord
- Models Page Makeover: An update on the /models page has been announced, promising new improvements and seeking community feedback here.
- Changes to token sizes for Gemini and PaLM will standardize stats but also alter pricing and context limits; the community will face adjustments.
- Defaulting from Default Models: The Default Model in OpenRouter settings is facing deprecation, with alternatives like model-specific settings or auto router coming to the forefront.
- Custom auth headers for OpenAI API keys are also being phased out, indicating a shift towards newer, more reliable methods of authentication.
- Discord Bot Dialogues Get Lean: Community members shared tips for optimizing conversation bots, emphasizing token-efficient strategies like including only necessary message parts in prompts.
- This opens discussion on balancing model context limits and maintaining engaging conversations, with a nod to the SillyTavern Discord's approach.
- Claude 3.5's Code Quarrels: Intermittent errors with Claude 3.5 are causing a stir, while Claude 3.0 remains unaffected, indicating a possible model-specific issue.
- The community is actively sharing workarounds and awaiting fixes, highlighting the collaborative nature of debugging in the engineering space.
- iOS Frontends Find OpenRouter Fun: Inquiries about iOS apps supporting OpenRouter were met with recommendations, with Pal Chat and Typingmind leading the charge post-bug fixes.
- The engagement on finding diverse frontend platforms suitable for OpenRouter integration suggests a growing ecosystem for mobile AI applications.
OpenAccess AI Collective (axolotl) Discord
- Eager vs Flash: Attention Heats Up for Gemma2: Eager attention is recommended for training Gemma2 models, with the setting modified to 'eager' in AutoModelForCausalLM.from_pretrained() for enhanced performance.
- Configuring YAML files for eager attention received thorough coverage, offering granularity for training Gemma2 to meet performance benchmarks.
- Optimizing Discussion: Assessing Adam-mini and CAME: There's a buzz around integrating CAME and Adam-mini optimizers within axolotl, circling around their lower memory footprints and potential training stability.
- Adam-mini surfaced as a rival to AdamW for memory efficiency, sparking a discussion on its pragmatic use in large model optimization.
- Getting the Measure: Numerical Precision over Prose: A user sought to prioritize precise numerical responses over explanatory text in model outputs, pondering the use of weighted cross-entropy to nudge model behavior.
- While the quest for research on this fine-tuning method is ongoing, the community spotlighted weighted cross-entropy as a promising avenue for enhancing model accuracy.
- Gemma2's Finetuning Frustrations Grapple Gradient Norm Giants: Finetuning woes were shared regarding Gemma2 27b, with reports of high grad_norm values contrasting with smoother training experiences on smaller models like the 9b.
- Lower learning rates and leveraging 'flash attention' were among the proposed solutions to tame the grad_norm behemoths and ease Gemma2's training temperament.
- ORPO's Rigid Rule: Pairs a Must for Training: A member grappled with generating accepted/rejected pairs for ORPO, seeking confirmation on whether both were required for each row in training data.
- The community consensus underscored the critical role of pair generation in ORPO's alignment process, emphasizing its trickiness in practice.
LlamaIndex Discord
- Llama-Leap to Microservices: Mervin Praison designed an in-depth video tutorial on the new llama-agents framework, outlining both high-level concepts and practical implementations.
- The tutorial, widely acknowledged as comprehensive, drills down into the intricacies of translating Python systems to microservices, with community kudos for covering advanced features.
- Knowledge Assistants Get Brainy: The AI Engineer World Fair showcased breakthrough discussions on enhancing knowledge assistants, stressing the need for innovative data modules to boost their efficiency.
- Experts advocated for a shift towards sophisticated data handling, a vital leap from naive RAG structures to next-gen knowledge deepening.
- Microsoft's Graph RAG Unpacked: Microsoft's innovative Graph RAG Architecture made a splash as it hit the community, envisioned as a flexible, graph-based RAG system.
- The reveal triggered a wave of curiosity and eagerness among professionals, with many keen to dissect its potential for modeling architectures.
- Pinecone's Pickle with Metadata: Technical challenges surfaced with Pinecone's metadata limits in handling DocumentSummaryIndex information, compelling some to code workarounds.
- The troubleshooting sparked broader talks on alternative frameworks, underscoring Pinecone's rigidity with metadata handling, inspiring calls for a dynamic metadata schema.
- Chatbots: The RAG-tag Revolution: AI engineers broached the development of a RAG-based chatbot to tap into company data across diverse SQL and NoSQL platforms, harnessing LlamaHub's database readers.
- The dialog opened up strategies for formulating user-text queries, with knowledge sharing on database routing demonstrating the community's collaborative troubleshooting ethos.
tinygrad (George Hotz) Discord
- Graph Grafting Gains Ground: Discourse in Tinygrad centered on enhancing the existing
graph rewrite followup, speedup / different algorithm, with consensus yet to form on a clear favorite algorithm. Egraphs/muGraphs have been tabled for future attention.- Although not Turing complete, members boldly bracketed the rule-based approach for its ease of reasoning. A call for embedding more algorithms like the scheduler in graph rewrite was echoed.
- Revealing the Mystique of 'image dtype': Tinygrad's 'image dtype' sparked debates over its ubiquitous yet cryptic presence across the codebase; no specific actions to eliminate it have been documented.
- Queries such as 'Did you try to remove it?' circled without landing, leaving the discussion hanging without detailed exploration or outcomes.
- Whispers of Error Whisperers: Tinygrad's recurrent error RuntimeError: failed to render UOps.UNMUL underscored an urgent need to overhaul error messaging as Tinygrad navigates towards its v1.0 milestone.
- George Hotz suggested it was more an assert issue, stating it should never happen, while a community member geared up to attack the issue via a PR with a failing test case.
- Memory Mayhem and Gradient Wrangling: Lively discussions pinpointed the CUDA memory overflow during gradient accumulation in Tinygrad, with users exchanging strategies such as reducing loss each step and managing gradient memory.
Tensor.no_grad = Trueemerged as Tinygrad's torchbearer against gradient calculations during inference, drawing parallels withtorch.no_grad(), anda = a - lr * a.gradas the modus operand becausea -= lr * a.gradtriggers assertions.
- Documentation Dilemmas Demand Deliberation: Championing clarity, participants in Tinygrad channels appealed for richer documentation, especially covering advanced topics like TinyJit and meticulous gradient accumulation.
- As developers navigate the balance between innovation and user support, initiatives for crafting comprehensive guides and vivid examples to illuminate Tinygrad's darker corners gained traction.
LangChain AI Discord
- RAG-Tag Matchup: HydeRetrieval vs. MultiQueryRetrieval: A heated conversation unfolded around the superiority of retrieval strategies, with HydeRetrieval and MultiQueryRetrieval pitted against each other. Several users chimed in, one notably experiencing blank slates with MultiQueryRetrieval, triggering a discussion on potential fallbacks and fixes.
- The debate traversed to the realm of sharded databases, with a curious soul seeking wisdom on implementing such a system. Insights were shared, with a nod toward serverless MongoDB Atlas, though the community's thirst for specifics on shard-query mapping remained unquenched.
- API Aspirations & File Upload Queries: In the domain of LangServe, a conundrum arose about intertwining fastapi-users with langserve, aiming to shield endpoints with user-specific logic. The echo chamber was quiet, with no guiding lights providing a path forward.
- Another LangChain aficionado sought guidance on enabling file uploads, aspiring to break free from the confines of static file paths. A technical crowd shared snippets and insights, yet a step-by-step solution remained just out of grasp, lingering in the digital fog.
- LangChain Chatbots: Agents of Action: Among the LangChain templars, a new quest was to imbue chatbots with the prowess to schedule demos and bridge human connections. A response emerged, outlining using Agents and AgentDirector, flourishing with the potential of debugging through the lens of LangSmith.
- The lore expanded with requests for Python incantations to bestow upon the chatbots the skill of action-taking. Responses cascaded, rich with methodological steps and tutorials, stirring the pot of communal knowledge for those who dare to action-enable their digital creations.
- CriticGPT’s Crusade and RAFT’s Revelation: OpenAI’s CriticGPT stepped into the limelight with a video exposé, dissecting its approach to refining GPT-4's outputs and raising the bar for code generation precision. Keen minds absorbed the wisdom, contemplating the progress marked by the paper-linked video review.
- The forward-thinkers didn't rest, probing the intriguing depths of RAFT methodology, sharing scholarly articles and contrasting it against the age-old RAG mechanics. A beckoning call for collaboration on chatbots using LLM cast wide, with an open invitation for hands to join in innovating.
Latent Space Discord
- Runway Revolution with Gen 3 Alpha: Runway unveiled Gen-3 Alpha Text to Video, a tool for high-fidelity, fast, and controllable video generation, accessible to all users. Experience it here or check the announcement here.
- A head-to-head comparison with SORA by the community underscores Gen-3 Alpha's unique accessibility for immediate use, offering a glimpse into the future of video generation. You can see the side-by-side review here.
- Sonnet Syncs with Artifacts: The fusion of Sonnet with Artifacts is praised for boosting efficiency in visualizing and manipulating process diagrams, promoting a more intuitive and rapid design workflow.
- Enthusiasts express admiration for the ability to synthesize visual concepts at the speed of thought, negating the tedium of manual adjustments and streamlining the creative process.
- Figma Debunks Design Data Doubts: Figma responded to user concerns by clarifying its 'Make Design' feature is not trained on proprietary Figma content, with the official statement available here.
- Despite Figma’s explanations, community discourse speculates over recognizable elements in outputs such as the Apple's Weather app, stirring an ongoing debate on AI-generated design ethics.
- Microsoft's Magnified Phi-3 Mini: Microsoft enhanced the Phi-3 Mini, pushing the limits of its capabilities in code comprehension and multi-language support for more effective AI development. Check out the update here.
- Improvements span both the 4K and 128K models, with a focus on enriching the context and structured response aptitude, heralding advancements in the nuanced understanding of code.
- Magic Dev's Market Magic: Startup Magic Dev, despite lacking concrete product or revenue, is targeting an ambitious $1.5 billion valuation, spotlighting the fervent market speculation in AI. Details discussed on Reuters.
- The valuation goals, set by a lean 20-person team, points to the AI investment sphere's bullish tendencies and renews concerns about a potential bubble in the absence of solid fundamentals.
Mozilla AI Discord
- Llama.cpp on Lightweight Hardware? Think Again: Discussions on running llama.cpp revealed that neither iPhone 13 nor a Raspberry Pi Zero W meet the 64-bit system prerequisite for successful operation, with specific models and memory specs essential.
- Community members pinpointed that despite the allure of portable devices, models like the Raspberry Pi Zero fall short due to system and memory constraints, prompting a reevaluation of suitable hardware.
- Llamafile v0.8.9 Takes a Leap with Android Inclusion: Mozilla announced the launch of llamafile v0.8.9 with enhanced Android compatibility and the Gemma2 model more closely mirroring Google's framework.
- Feedback heralded the version's alignment improvements for Gemma2, suggesting it could now rival larger models according to public assessments.
- Mxbai Model Quirk Fixed with a Simple Switch: A peculiar behavior of the mxbai-embed-large-v1 model, returning identical vectors for varied text inputs, was resolved by changing the input key from 'text' to 'content'.
- Continued refinement was signaled by the community's recommendation to update the model on Hugging Face for clarity and ease of future deployments.
- Navigating the Hardware Maze for Large Language Models: AI enthusiasts convened to determine an optimal hardware setup for running heavyweight language models, with a consensus on VRAM heft and CPU memory prowess dominating the dialogue.
- Practical insights from users favored 3090/4090 GPUs for mainstream usage while advocating for A6000/RTX 6000 workstations for those pushing the boundary, emphasizing the trial and balance of a conducive hardware configuration.
- The Great CPU vs GPU Debate for Model Training: GPUs remain the preferred platform over CPUs for model training, owning to their computational prowess, as exhibited by the slow and inadequate processing capabilities of multicore CPUs when tasked with large models.
- Speculations about the feasibility of CPU-based training brewed, with community testing using llm.c to train models like GPT-2, highlighting the stark limitations of CPUs in large-scale learning applications.
OpenInterpreter Discord
- Windows Woes & Wins: Users grappled with challenges in Building 01 on Windows, with piranha__ unsuccessfully searching for guidance, while stumbling upon a potentially salvaging pull request that promises to update the installation guide.
- The discussed pull request compiles past users' attempts to conquer the installation ordeal on Windows, potentially ironing out wrinkles for future endeavours.
- Troubleshooting Concurrency in OI: chaichaikuaile_05801 discussed the perplexities of concurrency and resource isolation with OI deployments, debating over the benefits of OI Multiple Instances versus other contextual solutions.
- The exchange considered the use of
.reset()to circumvent code-sharing snags, concluding that disparate instances escape the turmoil of shared Python execution environments.
- The exchange considered the use of
- Pictorial Pickles in OI: A poignant plea by chaichaikuaile_05801 highlighted the hurdles faced when displaying images through OI's
MatPlotLib.show(), referencing an open GitHub issue showing the discrepancies between versions.- As the user navigates between versions 0.1.18 and 0.2.5, they call for future versions to bolster image return functionalities, indicating a thirst for visualization improvements.
- In Quest of Quantum Local AI Agents: blurrybboi sought out Local AI Agents with the prowess to prowl the web beyond basic queries, targeting those that can sift through chaff to cherry-pick the prime output.
- Despite the entreaty, responses were nil, leaving unanswered the question of AI agents' aptitude in advanced online filtration.
Torchtune Discord
- WandB Wins for Workflow: A user celebrated their win in finetuning a model successfully, overcoming the need for a personal GPU by leveraging online resources, and embraced WandB for better training insights.
- Community discussions concluded that streamlining YAML configurations and adopting WandB's logger could simplify the training process, as per the shared WandB logger documentation.
- AMD's AI Antics Assessed: Members exchanged experiences on utilizing AMD GPUs for AI purposes, recommending NVIDIA alternatives despite some having success with ROCm and torchtune, as detailed in a Reddit guide.
- A user expressed their struggled journey but eventual success with their 6900 XT, highlighting community support in troubleshooting torchtune on AMD hardware.
- HuggingFace Hug for Torchtune Models: An inquiry was made into converting torchtune models to HuggingFace's format, indicating the user's intent to merge toolsets.
- While specifics of the conversion process were not discussed, participants shared naming conventions and integration strategies, showing the engineering efforts in model compatibility.
Cohere Discord
- Multi-Step Marvels with Cohere's Toolkit: Toolkit multi-step capabilities have been confirmed by users, featuring enabled frontend and backend support, with shared examples in action.
- Discussions also applauded Sandra Kublik's session at AI Engineer in SF, and emphasized the sunset of the LLM-UNIVERSITY channel, directing users to Cohere's API documentation for continued support.
- Slack Bot's Speedy Sync-Up: A user created a Cohere Slack bot expressing its ease of use in the workspace, praised by the community with immediate reactions.
- The conversation underlined the importance of fast model processing due to Slack's 3-second rule for bots, spotlighting the need for responsive AI models.
- London Calling for AI Enthusiasts: An announcement for Cohere For AI's upcoming London event on July 10th focuses on multilingual AI, with exciting activities like lightning talks and the kickoff of Expedition Aya.
- Expedition Aya is a global challenge pushing the boundaries of multilingual AI models, offering teams exclusive resources, API credits, and the chance to win swag and prizes for notable contributions.
LAION Discord
- Model Evaluation Maze: An article detailed the complex landscape of evaluating finetuned LLMs for structured data extraction, emphasizing the intricate metric systems and the tedium of the process without a solid service to maintain evaluations. The focus was on the accuracy metric and the hidden layers of code that often slow down the work.
- The user highlighted the growing challenge of LM evaluation, citing resource demands and difficulty in preserving the integrity of the evaluations over time. No additional resources or diagrams were shared.
- Resounding phi-CTNL Triumph: A groundbreaking paper introduced phi-CTNL, a lean 1 million parameter LLM, showcasing its perfect scores across various academic benchmarks and a grokking-like ability for canary prediction. The paper's abstract presents the full details of the model's prowess.
- This transformer-based LLM, pretrained on an exclusively curated dataset, stands out for its capacity to predict evaluation benchmarks with pinpoint accuracy, sparking discussion across the AI engineering community about the potential applications of such a nimble yet powerful model.
- AIW+ Problem Cracked: One user presented evidence that a correct solution to the AIW+ problem has been authenticated, suggesting the use of a diagram for a formally checked answer. They cited an accurate response from the model Claude 3 Opus as validation.
- The solution's confirmation sparked a discourse on the assumptions utilized in problem statements and how they directly influence outcomes. Investigators are urged to inspect the logic that underpins these AI puzzles closely.
- Terminator Architects: A new model architecture named 'Terminator' has been proposed, featuring a radical departure from traditional designs by eliminating residuals, dot product attention, and normalization.
- The Terminator model was shared in the community, with a paper link provided for those interested in exploring its unique structure and potential implications for model developments.
LLM Finetuning (Hamel + Dan) Discord
- Chainlit Cooks Up a Sound Solution: An AI engineer combined SileroVAD for voice detection with whisper-fast for transcription, advising peers with a Chainlit audio assistant example. TTS alternatives like elevenlabs (turbo), playht, and deepgram were also reviewed for optimizing audio workflows.
- Further discussion revolved around knowledge graphs and the utilization of Lang Graph in AI, with community members actively seeking deeper insights into embedding graph technologies into AI systems.
- Dask's Dive into Data Dimensionality: Engaging with large datasets, particularly from the USPTO Kaggle competition, led to out of memory (OOM) errors when using Dask. The talk turned towards strategies for using Modal to efficiently execute Dask jobs, aiming to manage massive data volumes.
- One practitioner queried the group about success stories of running Dask jobs on Modal, hinting at Modal's potential to better accommodate high-demand computational workloads.
- Autotrainer or Not? That's the Question: Autotrainer's role was questioned, with ambiguity about whether it pertained to Axolotl's features or Huggingface autotrain. The community engaged in an effort to pinpoint its association.
- The source of Autotrainer remained unclear, with at least one guild member seeking clarification and later conjecturing a connection to Huggingface autotain after some investigation.
- OpenAI's Generosity Grapples Guilt: OpenAI's pricing caused a mix of humor and guilt among users, with one lamenting their inability to exhaust their $500 credits in the provided 3-month period.
- This sentiment was shared by another member, who amusingly adopted an upside-down face emoji to express their mixed feelings over the undemanding credit consumption.
- The Slide Deck Side-Quest: Dialogue ensued over the location of a video's slide deck—with members like Remi1054 and jt37 engaging in a hunt for the elusive presentation materials, often hosted on Maven.
- The pursuit continued as hamelh signified that not all speakers, like Jo, readily share their decks, compelling practitioners to directly request access.
AI Stack Devs (Yoko Li) Discord
- Hexagen.World Unveils New Locales: Fresh locations from Hexagen.World have been introduced, expanding the digital terrain for users.
- The announcement sparked interest among members for the potential uses and developments tied to these new additions to the Hexagen.World.
- AI Town Docks at Docker's Shore: Community voices call for a Docker port of AI Town, discussing benefits for enhanced portability and ease of setup.
- A proactive member shared a GitHub guide for setting up AI Town on Windows using WSL, with suggestions to integrate it into the main repository.
Interconnects (Nathan Lambert) Discord
- Apple Nabs OpenAI Seat with Panache: Phil Schiller is set to join the OpenAI board as an observer, giving Apple an edge with a strategic partnership aimed at enhancing their Apple Intelligence offerings, outlined here.
- The AI community bubbled with reactions as Microsoft's hefty investment contrasted sharply with Apple's savvy move, sparking debate and a bit of schadenfreude over Microsoft's disadvantage as seen in this discussion.
- Tech Titans Tussle Over OpenAI Ties: Conversations among the community delve into the business dynamics of OpenAI partnerships, examining Apple's strategic win in gaining an observer seat vis-à-vis Microsoft's direct financial investment.
- Insights and jibes threaded through the discourse, as participants compared the 'observer seat deal' to a game of chess where Apple checkmates with minimal expenditure, while Microsoft's massive outlay drew both admiration and chuckles from onlookers.
Datasette - LLM (@SimonW) Discord
- Web Wins with Wisdom: Be Better, Not Smaller analyzes the missteps of early mobile internet services like WAP, likening them to modern AI products. It explains the limitations of pre-iPhone era mobile browsing and suggests a better approach for current products.
- The article encourages current AI developers to prioritize enhancing user experiences over simply fitting into smaller platforms. Mobile browsing was once like "reading the internet by peering through a keyhole."
- Governing Gifts Gather Gawkers: A Scoop article reveals the array of unusual gifts, such as crocodile insurance and gold medallions, received by U.S. officials from foreign entities.
- It discusses the difficulties in the data management of these gifts, pointing out their often-unstructured format and storage issues, which reflects a larger problem in governmental data handling. "These foreign gifts really are data."
PART 2: Detailed by-Channel summaries and links
{% if medium == 'web' %}
LM Studio ▷ #💬-general (193 messages🔥🔥):
LM Studio updates and issues,TTS integration in LM Studio,Model recommendations for local use,Challenges with large model loading,Gemma 2 model performance and updates
- LM Studio updates & issues: Members discussed various issues and updates related to LM Studio including network errors, the need to update certain models like Gemma 2, and questions about system requirements and performance improvements.
- "We’re planning to release an update tomorrow (USA)" was announced, followed by community interactions resolving issues with VRAM and loading large models.
- TTS integration in LM Studio questioned: A member asked about the Text-to-Speech (TTS) integration within LM Studio and the feasibility of running both TTS and LM Studio on the same server.
- No definitive answers were given, signaling further interest in exploring TTS capabilities within the application.
- Local model recommendations and issues: Members recommended various local models for tasks like game translation, specifically Meta-LLaMA 3 and discussed issues with models being overly literal.
- Experts favored models like Gemma 2 for their writing style and performance, particularly recommending certain quantizations for systems with limited VRAM.
- Challenges with large model loading in LM Studio: Several users reported issues with loading large models like 30B and 70B parameters in LM Studio despite having sufficient hardware.
- It was noted that split models can have loading issues related to RAM limits, and that full GPU offload is often required for optimal performance.
- Gemma 2 model performance and updates: Gemma 2's latest updates improved performance significantly, with users noting better coherence and narrative capabilities after the update.
- Discussions included the necessity to re-download updated GGUF files for optimal performance and integration with applications like Langchain and Local Server.
Links mentioned:
LM Studio ▷ #🤖-models-discussion-chat (148 messages🔥🔥):
Model performance and loading times,Phi-3 Mini update,Running models on different hardware,Excessive GPU idling temperature with LM Studio,Quantizing vision models for LM Studio
- Model performance and loading times: Users discussed the performance issues and slow loading times of large models on different hardware setups, citing an example of a 70b model running at 0.04 tokens/s on NVME storage due to insufficient RAM.
- One user recommended trying smaller, quantized models like Mistral Grok 7b Q5, which performed better on limited hardware with speeds of 3-5 tokens/s.
- Phi-3 Mini update debuts: Microsoft released updates for Phi-3 Mini, addressing instruction following and output structure. Links to the updated models are available on Hugging Face.
- Users are testing the updated models' performance, with some noting issues loading the 128k context model while others struggle to get the Mini 4k Q8_0 running properly.
- Users struggle with GPU idling temperatures in LM Studio: Members observed high idle temperatures for GPUs when running LM Studio, reporting examples like a P40 GPU idling at 47C at 45% fan speed.
- The issue does not occur with other applications like Ollama or ComfyUI, suggesting a possible problem specific to LM Studio.
- Running models on varied hardware configurations: Discussions included configuring hardware setups to run large models effectively, with suggestions like using different disks for output to speed up processes and leveraging NVME over HDD.
- There were also suggestions to use external scripts or programs like langchain to enable models to access the internet or runtime data, highlighting the flexibility and limitations of LM Studio.
- Exploring quantized vision models for LM Studio: Users expressed interest in running large vision models like dolphin-vision-72B in LM Studio and discussed the challenges associated.
- Though quantization could potentially make these models fit into available VRAM, experience and guidance on vision models within LM Studio remain limited.
Links mentioned:
LM Studio ▷ #announcements (1 messages):
LM Studio 0.2.27 release,Improved support for Gemma 2 models,Bug fix for 'invalid creation parameter' issue,Advanced information on new updates,ROCm extension pack instructions for Windows
- LM Studio 0.2.27 released with Gemma 2 support!: LM Studio 0.2.27 is now available for Mac (M1/M2/M3), Windows (x86 and ARM64), and Linux (x86), featuring improved performance for Gemma 9B and 27B models. Download it from here or restart your app to trigger an auto-update.
- Bug fix resolves 'invalid creation parameter' issue: The latest update includes a fix for the 'invalid creation parameter' bug in lmstudio.js issue #45. Users should see fewer error messages about GPU support.
- A related GitHub issue detailed the problem and resolution, ensuring smoother performance.
- Advanced updates in LM Studio: The
llama.cppcommit ID has been updated tod08c20eddedb24515a3212e2de66bdff41a26b8c, and theOpenCLbackend is re-bundled with LM Studio for Windows and Linux. Notably, Gemma 2 is NOT supported for OpenCL.- For AMD ROCm users on Windows, see the instructions on how to update your ROCm extension pack. The Linux ROCm extension pack is still pending release.
Links mentioned:
LM Studio ▷ #🧠-feedback (9 messages🔥):
Request for a channel in Norwegian,LM Studio update compatibility issues with AMD Radeon 7800 XT,Suggestions for handling GPU compatibility errors in LM Studio,ROCM handling changes in LM Studio 0.2.26,Vulkan backend support as a potential solution
- Norwegian channel request handled smoothly: A member requested the creation of a channel for Norwegian, referring to the compliance with guidelines. Another member clarified that they can create the thread themselves without restrictions, ensuring flexibility.
- You should be able to create the thread yourself, a member reassured, highlighting the platform's flexibility. I was only complying to the rules, the requester noted, acknowledging the guidelines.
- AMD Radeon 7800 XT hits unexpected compatibility snag: A member reported that after the latest LM Studio update, their AMD Radeon 7800 XT 16GB VRAM GPU is marked incompatible even though it was working previously. They mentioned experiencing excellent performance prior to the update.
- A link to Extension-Pack-Instructions.md was shared explaining ROCM handling changes. 0.2.26 changed the way ROCM is handled, explained another member.
- Error messages in LM Studio need refinement: Community feedback indicated the need for improved error messaging to help users troubleshoot GPU compatibility issues themselves. Multiple reports were noted since the latest update.
- Good suggestion. 0.2.27 brings back OpenCL, confirmed an update to address some of these issues. Another member suggested that Vulkan backend support will solve 90% of these issues.
Links mentioned:
LM Studio ▷ #🎛-hardware-discussion (47 messages🔥):
Transformers ASICs market potential,Sohu expected pricing,VRAM vs RAM for LLM inference,AMD GPU support issues in LM Studio,Enhanced GPU setups for LLM processing
- Transformers ASICs have market potential: Discussion suggests a demand for GPUs tailored for LLMs, emphasizing 144GB VRAM and dedicated chips for LLM tasks only.
- Concerns about initial high costs, with claims that ASICs are the only feasible solution for large-scale inference, such as in Etched.
- VRAM vs RAM for LLM Inference: Members advise that VRAM is more critical for LLM inference tasks, with 8GB VRAM preferred over 4GB for better performance.
- One member highlighted that running models entirely in VRAM results in superior speeds compared to split usage with system RAM.
- AMD GPU support issues in LM Studio: AMD GPUs were noted as not being recognized by LM Studio version 0.2.24, even for embedded GPUs.
- A member pointed out that OpenCL GPU support is deprecated in llama.cpp, causing these issues.
- Enhanced GPU setups for LLM processing: A member is upgrading from 3x air-cooled to 5x water-cooled 4090s for LLM inference, noting a significant total of 120GB VRAM.
- Heat and power management are primary concerns, with discussions about PSU requirements and external radiators.
- Optimizing LLMs on varied hardware: Members discussed running LM Studio on diverse setups, including Snapdragon and multi-GPU systems, with varying success.
- Reports of 19 t/s on 7b models and the need for tweaking configurations for best results, especially with integrations like SillyTavern.
LM Studio ▷ #autogen (2 messages):
LM Studio compatibility with group chat feature in autogen,Error handling with Llama 7b Instruct,Solutions for using LM Studio with multiple local models
- Compatability Issues with LM Studio's Group Chat Feature: A member experiences issues with LM Studio's groupchat feature when using Llama 7b Instruct, encountering a BadRequestError: Error code: 400 due to non-empty 'content' field requirement. They noted that the error does not occur with OpenAI models.
- Another member confirmed that several users have faced similar problems and recommended searching the Discord for solutions. They shared a link to a notebook demonstrating how to use AutoGen with multiple local models via LM Studio.
- Using Multi-Model Serving with LM Studio: The shared notebook details the use of AutoGen with LM Studio’s multi-model serving feature, available since version 0.2.17. It shows how to start a 'Multi Model Session' and load models for local hosting.
- The example includes creating a comedy chat using two different local models, Phi-2 and Gemma, and demonstrates creating configurations and starting the server for multi-model serving. The member emphasized this solution for any similar integration issues.
Link mentioned: LM Studio | AutoGen: Open In Colab
LM Studio ▷ #amd-rocm-tech-preview (17 messages🔥):
ROCm extension performance,Code benchmark results,NVIDIA GPU for AI,Gemma 2 model issues,ROCm-specific GPUs,Linux ROCm extension pack testing
- ROCm extension boosts performance: A member noted a decent uplift in performance with the ROCm extension on their 6900 XT GPU using the latest 24.6.1 Adrenalin drivers. The benchmark showed an increase from 9.29 tok/s to 26.75 tok/s with codestral 22b q4_k_m.
- Another member suggested that it's good to compare the differences, while a different member is reconsidering their purchase of an NVIDIA GPU for additional speed.
- Gemma 2 model fails to load: A user reported issues getting Gemma 2 to work, receiving a 'failed to load model' error after clearing caches and running scripts in LM Studio version 0.2.27. The error indicated an 'unknown model architecture' for 'gemma2' on an AMD 6900 XT GPU.
- "Re-download/clean install is always a good debug step," suggested another member, advising to create a post in the support channel if issues persist.
- ROCm works on specific GPUs: A member mentioned that ROCm only works on certain GPUs, listing the 6900 XT as compatible. They reported running Gemma 2 at 8k tokens without running out of RAM, a significant improvement over 2k tokens.
- This user also indicated that they might cancel the download of a more quantized version due to the successful performance.
- Call for Linux ROCm extension testing: A community call was made for members to assist in testing the latest Linux ROCm extension pack for version 0.2.27. Instructions included installation steps and a check for 'ROCm llama.cpp' under the 'Settings->GPU Backend Type' after running a specific script.
- Testers were thanked in advance and encouraged to report back their findings.
LM Studio ▷ #model-announcements (2 messages):
Phi 3 mini update to Phi 3.1 by Microsoft,Gemma 2 model updates for lmstudio community
- Microsoft's Phi 3.1 Mini Drops with Massive Improvements: Microsoft has updated Phi 3 mini to Phi 3.1, touting vastly better performance, improved instruction following, and enhanced output structuring. This update is available now on the lmstudio community.
- Gemma 2 Models Updated for Latest lmstudio Changes: The Gemma 2 models in the lmstudio community have been updated to include the latest changes. Users can safely redownload and use them with version 0.2.27.
- Links to the updated models are provided: Gemma 2 9b it GGUF and Gemma 2 27b it GGUF.
Link mentioned: lmstudio-community/Phi-3.1-mini-4k-instruct-GGUF · Hugging Face: no description found
LM Studio ▷ #🛠-dev-chat (50 messages🔥):
LM Studio load command error after update,TokenInvalid error in Discord bot,Configuring LM StudioClient,Discord bot intents and permissions,Debugging and fixing Discord bot code
- LM Studio load command fails post-update: After updating LM Studio from 0.2.25 to 0.2.26 and lmstudio.js SDK from 0.0.3 to 0.0.12, a user experienced errors when calling
await client.llm.load(modelPath);due to communication protocol incompatibility.- The error message suggested that the
creationParameter.loadConfigStackwas required, which prompted the user to open an issue on GitHub.
- The error message suggested that the
- TokenInvalid error resolved by Discord community: A user encountered a TokenInvalid error when setting up their Discord bot, which led them to consult the Discord.js community for guidance. The issue was traced back to disallowed MessageContent intents.
- After enabling the necessary intents for the bot, the user successfully resolved the issue, allowing the bot to login and function correctly.
- Client.login fails in bot with valid token: A user's Discord bot failed to login with an error suggesting an invalid token, even though the token was correctly configured. The base working code verified that the token itself was not at fault.
- Further investigation revealed that MessageContent intent was not enabled, causing the login failure.
- LM StudioClient configuration: A user shared their configuration for loading a specific model in LM Studio with custom settings including
gpuOffloadandcontextLength.- Although initially commented out, their daemon setting ensured the model remained loaded, allowing the user to reference it directly.
- Assistance provided for custom bot interactions: A user sought assistance to expand their Discord bot's functionality, including response to mentions and local conversation saving.
- Collaborative debugging and guidance led to adjusting bot permissions and fixing a flawed implementation in their TypeScript code.
Links mentioned:
HuggingFace ▷ #announcements (1 messages):
Access tons of new fine-tunes for Transformers models with KerasNLP.,Search Hugging Face datasets by column names with new API.,Transformers 4.42 release with new models and features.,Nearly 100k public models use the Hub to store tensorboard logs.,Local Gemma announced for private and secure usage.,AWS releases Chronos datasets on Hugging Face.,Google releases high-quality Gemma 2 LLMs.,Real-time Detection Transformer (RT-DETR) available in Hugging Face.,Florence-2 runs locally with WebGPU in the browser.,Intro to vision language models announced.,New challenging LLM leaderboard released.,Data Explorer video series by Argilla announced.,Efficient PyTorch dataloaders for distributed training.,New RAG with Gemma recipe using elastic search.
- Transformers 4.42 Brings New Features: Transformers 4.42 is released with new models like Gemma 2, RT-DETR, InstructBlip, and LLaVa-NeXT-Video, along with tool usage, RAG support, GGUF fine-tuning, and quantized KV cache as per release notes.
- The update is described as having amazing features with lots of enthusiastic community responses. One member remarks: Enjoy! 🥳.
- AWS Releases Chronos Datasets: AWS has released all the datasets used in the Chronos paper on Hugging Face, including both pretraining and evaluation datasets (more info). This also includes a script to evaluate Chronos models.
- An enthusiastic announcement mentions that the release includes evaluation in the same settings as in their paper and is described as 🚀🚀🚀.
- Nearly 100k Public Models Use Hub: Nearly 100k public models use the Hub to store
tensorboardlogs, allowing tracking of training logs alongside checkpoints (source). The Metrics tab consolidates everything in a single place.- A community member celebrates this milestone, referring to it as a way to keep track of everything in a single place.
- Google Brings High-Quality Gemma 2 LLMs: Google has released Gemma 2 with 27B + 9B parameters, designed to be high quality and with sizes friendly to developers (details).
- The release is highlighted as an important addition, with community members praising the model's impressive capabilities.
- Florence-2 Runs Locally with WebGPU: Microsoft's Florence-2, a new vision foundation model, can run 100% locally in your browser using WebGPU, thanks to Transformers.js (demo).
- It supports tasks like image captioning, optical character recognition, and object detection, and was described with WOW! by a member.
Links mentioned:
HuggingFace ▷ #general (318 messages🔥🔥):
Downloading Falcon40B and encountering issues,Comparison of Falcon 40B to other models like LLaMA 3,RAG (Retrieval-Augmented Generation) techniques and challenges,Parsing and managing large transcripts in LLMs,Summarization techniques for transcripts
- Falcon40B Download Woes: A user spent 30 minutes downloading ~90GB of Falcon40B files on a Linux machine only to find them missing. Discussion revealed the files are likely stored in HF's cache directory and suggested checking the path with a Python snippet.
- 'They are stored in HF's cache directory, and it won't download it again and HF automatically knows where it is.'
- Falcon 40B vs LLaMA 3: There was a debate on the relevance and performance of Falcon 40B versus newer models like LLaMA 3 and others. It was noted that Falcon 40B is considered outdated, with better, smaller models currently available.
- 'There are far, far better smaller models such as LLaMA 3 8B.'
- Challenges in RAG: Users discussed the intricacies of leveraging chunks, overlaps, L2 thresholds, and FAISS top_p for effective RAG implementations. A balance must be struck to avoid breaking context while retrieving documents.
- 'That the delicate art of balancing chunk_size, overlap, L2 thresholds, top_p (in FAISS) ... thus the need to create an eval dataset and run bulk inferences on different configs.'
- Handling Large Transcripts in LLMs: A user sought advice on managing a large transcript for a LLaMA 3 model but was directed to consider models with larger context windows like Mistral. The transcript exceeded 20k tokens, posing a problem for models with limited context handling.
- 'Depends on the 1k lines, but yes that's a bit too much I think. Use Mistral instead.'
- Summarization Strategies: Suggestions were made to summarize large transcripts to prevent breaking context and improve processing efficiency. It was emphasized that smart splitting strategies are crucial for effective summarization.
- 'In any case, a solution that doesn't split the transcript smartly won't work... read this article on chunking strategies in RAG for more context.'
Links mentioned:
HuggingFace ▷ #today-im-learning (2 messages):
diffusion models for learning,advanced CNN topics resources
- Diffusion Models for Learning Run Out of Compute: A user mentioned that they have 'run out of compute' while learning diffusion models and were using free Google Colab resources.
- No additional discussion or links were provided.
- Seeking Advanced CNN Resources: Another user asked for recommended books or resources to learn advanced topics in CNN such as ViT and Unets, including video processing.
- No additional discussion or links were provided.
HuggingFace ▷ #cool-finds (10 messages🔥):
AI figuring out meshes,Top 5 Python frameworks,AI and society paper,Running transformers on robots
- AI just figured out Meshes: A video titled AI just figured out Meshes was shared, showcasing a YouTube video and linking the original paper, demo, and code. This project is notably involved with Hugging Face.
- IndividualKex thanked a user for praising the coolness of the AI mesh project. osanseviero highlighted that the work is from the talented <@947993236755054633>.
- Running transformers on robots: A link to a GitHub repository was shared, showing a project titled embodied-agents that allows running transformers on any robot with a few lines of Python. The repository details the seamless integration of state-of-the-art transformer models into robotics stacks.
- The project appears engaging with its promise of simplifying robotics applications using transformers. Run transformers on any robot in just a few lines of Python was an eye-catching highlight.
Links mentioned:
HuggingFace ▷ #i-made-this (5 messages):
Vision-Language model for Vietnamese,AI and e-commerce projects,CriticGPT for code correction,Stable release of Embodied Agents toolkit
- Vision-Language Model Innovates Image Descriptions: A team introduced a Vision-Language model for Vietnamese, Vistral 7B, which performs well on image description tasks. The model is based on LLaVA, Vistral LLM, and synthetically generated datasets from Gemini API; details and resources are available on their GitHub and HuggingFace.
- They use the Siglip image encoder and leverage the Llava approach for further vision capabilities. Feedback and further research on the model's performance are encouraged via their posted demo.
- AI-Ecommerce Projects Showcase: Tony Assi shared a collection of AI and e-commerce projects with a focus on computer vision and stable diffusion. The projects span various innovative implementations in the e-commerce domain.
- Enjoy!
- CriticGPT Video Analysis: A YouTube video, OpenAI releases CriticGPT to correct GPT-4's mistakes, was shared, discussing OpenAI's new model: CriticGPT. The model aims to identify errors in GPT-4 generated code, marking an important step toward improved error correction.
- Harshit Tyagi invited feedback on their analysis of the paper in the video.
- Embodied Agents Toolkit Launched: A stable release of the open-source library Embodied Agents was announced on GitHub. The toolkit enables users to integrate state-of-the-art multimodal transformers into robotics with minimal code.
- The toolkit includes Gradio interface support and integration with HuggingFace datasets. Feedback is welcome as the developers seek to enhance user experience.
Links mentioned:
HuggingFace ▷ #reading-group (5 messages):
HyperZ⋅Z⋅W Operator Connects Slow-Fast Networks,Terminator architecture,Terminator code repository,Fast training convergence with Terminator architecture
- Terminator Architecture Now on GitHub: Terminator architecture code has been made public on GitHub. This architecture is known for connecting slow-fast networks for full context interaction.
- Members expressed interest in its fast training convergence; it can achieve satisfactory results with just 50~100 training epochs, which is 1/4~1/2 of the epochs required by other architectures.
- Terminator's Efficient Training Boasts Impressive Results: A member mentioned that the Terminator architecture could achieve impressive results in just 50~100 training epochs. This is significantly fewer than other architectures which often require 200+ epochs.
- The fast convergence rate was highlighted as a standout feature of the Terminator architecture, making it a potential game-changer in model training.
Link mentioned: GitHub - hyperevolnet/Terminator: The official repository for HyperZ⋅Z⋅W Operator Connects Slow-Fast Networks for Full Context Interaction.: The official repository for HyperZ⋅Z⋅W Operator Connects Slow-Fast Networks for Full Context Interaction. - hyperevolnet/Terminator
HuggingFace ▷ #computer-vision (4 messages):
Resources for learning advanced CNN topics like ViT and Unets,Interest in working on computer vision tasks,Prompting etiquette reminders
- AI Engineer seeks advanced CNN resources: A member inquired about books or resources for advanced CNN topics like ViT and Unets, including video processing. They're seeking recommendations for further learning.
- No responses or further details were provided.
- Prompting etiquette reminder in Discord: HuggingMod reminded a user not to post too quickly. The reminder aims to maintain a smooth conversation flow in the channel.
- No further discussion occurred on this topic.
HuggingFace ▷ #NLP (1 messages):
embedding numbers,specific embedding models
- Seeking Numerical Embedding Methods: Etienne83 inquired about methods to embed numbers or specific embedding models for numbers. No detailed responses were provided.
- No further discussion or opinions on this topic ensued.
- No Further Engagement: There were no additional responses or follow-ups to the question about embedding numbers. The topic did not generate further discussion.
- The conversation did not continue beyond the initial query.
HuggingFace ▷ #diffusion-discussions (2 messages):
Problem with LLama.cpp causing access violation error,Seeking pre-trained model recommendation for fake voice detection
- LLama.cpp Access Violation Error: A member reported encountering an OSError: access violation reading while using LLama.cpp in their Python script, specifically at the model loading stage.
- The error occurs at
llama_cpp::llama_load_model_from_file, leading to an access violation at address0x0000000000000000.
- The error occurs at
- Seeking Pre-trained Model for Fake Voice Detection: A member, who is a computer science student, is looking for recommendations for a pre-trained model that has good performance in fake voice detection.
- They mentioned they're working on a project to study fake voice detection models and are seeking community input on the best models to use.
CUDA MODE ▷ #general (3 messages):
CUDA-only hackathon at the AGI House in San Francisco,Participants receive H100 access for the hackathon
- H100-Powered Hackathon Announced: A CUDA-only hackathon is being organized at the AGI House in San Francisco on July 13th, hosted by Chris Lattner. Each participant will receive H100 access for the event, sponsored by Nebius AI.
- Emphasizing the use of CUDA, all projects must adhere to this requirement. Organizers aimed to set a high bar: "Let's blow away some baselines."
- AGI House Hackathon Event Details: The event starts at 12:00pm and ends at 10:00pm on Saturday, July 13. Location details will be shared with those who get on the list.
- The event is aiming for a hardcore hacker culture with strict rules on the use of CUDA. Discussions are happening on Twitter.
Link mentioned: RSVP to Hardcore CUDA Hackathon | Partiful: All talks and projects MUST be written in CUDA Every hardcore hacker gets a H100 for the day. All sponsored and proved by Nebius.ai! Let's blow away some baselines.
CUDA MODE ▷ #cool-links (1 messages):
mobicham: https://salykova.github.io/matmul-cpu
CUDA MODE ▷ #torchao (30 messages🔥):
INTx performance benchmarking,Quantization techniques in torchao,INT8-weight only vs INTx-4 implementation,Evaluation script batch sizes,Token per second trends with different INTx implementations
- INTx beats fp16: INTx performance testing outperforms fp16 in terms of accuracy and speed, with int2 and int4 showing significantly higher tokens per second.
- Members confirmed int8-weight and intx-4 performance are from
torchao.quantization.quant_api, noting that int8 and higher may not be as useful due to sufficient accuracy with INT8.
- Members confirmed int8-weight and intx-4 performance are from
- Batch size for evaluation: The evaluation scripts are using a batch size of 1 for INTx performance testing.
- It's noted by members that this setup is expected to work best at batch size of 1 and evaluations are ongoing.
- Token per second trends: Token per second rates show a clear trend: multiples of 2 (like int2 and int4) outperform others due to their shard usage.
- INT4 is the fastest because it uses a single 4-bit shard, while INT7 is the slowest due to multiple shards (4-bit, 2-bit, and 1-bit).
Link mentioned: executorch/examples/models/llama2 at main · pytorch/executorch: On-device AI across mobile, embedded and edge for PyTorch - pytorch/executorch
CUDA MODE ▷ #hqq (5 messages):
Benchmark results script request,Token/second calculation code request,Transformer update issues
- MobiusML Shares Benchmark Scripts: MobiusML shared scripts used for benchmark results, linking to torchao_int4_demo and marlin_int4_demo.
- It's still broken since transformers moved the static cache outside the model, planning to fix this week.
- Tokens/Second Calculation Code: MobiusML explained how to calculate tokens/second by running:
gen.generate("Write an essay about large language models.", print_tokens=False).- This was also broken with the latest transformers update, but fixed and now available in the master branch.
Links mentioned:
CUDA MODE ▷ #llmdotc (204 messages🔥🔥):
Improving helper and kernel functions in CUDA MODE,Discussion on GenericVector and its applications,Training stability with different datasets and model sizes,Streamlining the setup and memory usage optimization for llm.c,Investigating performance impacts with various configurations and settings,Exploring inference optimizations and platform simplifications
- CUDA Helpers: Improving Functionality: Members discuss improvements to helper and kernel functions to enhance code clarity and efficiency. Key improvements include making kernel setups cleaner and optimizing memory usage.
- Discussions include GenericVector and cleaner template functions for different GPU tasks: "ElementCount should be adjustable; but I think it makes sense to have convenience typedefs that make sense."
- Training Stability with Datasets: Identified training instabilities with FineWeb dataset on the 1.5B model, confirmed it to be correct by user akakak1337 and eliebak. Edu FineWeb dataset performed better, prompting further analysis.
- User akakak1337 noted that FineWeb-EDU had fewer instabilities compared to the *Classic variant, suggesting dataset quality impacts training stability.
- llm.c Setup and Optimization: Discussions focus on making the llm.c setup process more efficient, removing dependencies like miniconda and Python. New setup takes 1-5 minutes, making it easier for users to get started.
- Key steps include installing necessary libraries and cloning the repo with minimal setup instructions: "The instructions are super minimal: install cudnn, cudnn-frontend, openmpi, clone repo, download starter_pack, fineweb shards, run!"
- Investigating Performance and Configuration: Comparisons of memory usage and batch sizes show llm.c outperforming PyTorch significantly, fitting larger batch sizes in memory efficiently. Notably, batching issues arise under certain configurations, causing crashes at smaller batch sizes.
- User akakak1337 experienced crashes with batch sizes smaller than 4 due to division by zero errors: "integer division by zero error - crashes the run".
- Inference Optimization Discussions: Conversations about optimizing inference highlight the need for simplicity and efficiency, avoiding overheads like quantization for single-user setups. Points discussed include the potential benefits of streamlined implementation.
- Efficient use cases and possible future directions were discussed, emphasizing a streamlined approach: "...just something extremely simple to be OK-ish for single-user inference might be useful if it's much simpler than other frameworks as well."
Links mentioned:
CUDA MODE ▷ #rocm (1 messages):
Performance comparison of AMD MI300X and Nvidia H100 SXM on Mixtral 8x7B inference,Advantages of Nvidia's CUDA over AMD's ROCm for AI workloads,Developer preferences for Nvidia GPUs in AI production
- AMD MI300X Challenges Nvidia H100 SXM: The RunPod blog presents benchmarks showing AMD MI300X outperforming Nvidia H100 SXM on small and large batch sizes when running inference on Mistral's Mixtral 8x7B. The benchmark results highlight MI300X's superior specs.
- However, most developers don’t use AMD cards for real-life production workloads, since Nvidia's CUDA is miles ahead of AMD’s ROCm when it comes to writing software for machine learning applications.
- Nvidia's CUDA Dominates AI Software Development: Even though MI300X has better raw specs, developers prefer Nvidia GPUs for production workloads due to CUDA being far ahead of ROCm in ease of writing software for machine learning applications. The superior software ecosystem keeps Nvidia dominant despite AMD's hardware advances.
- The post emphasizes that Nvidia's historical dominance in AI training and inference is a major reason nearly all production AI workloads run on their graphics cards.
Link mentioned: AMD MI300X vs. Nvidia H100 SXM: Performance Comparison on Mixtral 8x7B Inference: There’s no denying Nvidia's historical dominance when it comes to AI training and inference. Nearly all production AI workloads run on their graphics cards. However, there’s been some optimism r...
CUDA MODE ▷ #sparsity (1 messages):
iss_llm: Thank you very much <@1213148470664495114> !
Perplexity AI ▷ #announcements (2 messages):
Voice-to-voice experience on Android app,Pro Search update with deeper research capabilities
- Voice-to-voice experience debuts on Android: The latest Android app version introduces a voice-to-voice experience with two modes: Hands-free and Push-to-talk. Users are encouraged to provide feedback in the designated channel.
- Hands-free mode starts listening as soon as the screen is opened, while Push-to-talk mode operates by pressing and holding the mic button.
-
Pro Search upgrade boosts complex query handling: An updated Pro Search now handles more complex queries through deeper research involving multi-step reasoning, Wolfram|Alpha, and code execution. The upgraded tool is designed to aid in in-depth research, mathematical problem-solving, and debugging code.
The improved search delivers more informed answers, supporting complex and detailed inquiries. More information can be found here.
Perplexity AI ▷ #general (211 messages🔥🔥):
Perplexity AI search engine issues and updates,Discussion on Claude's token limitations on Perplexity AI,Methods to generate graphs or visualizations using Perplexity,Referral links and promotional codes for Perplexity AI,Perplexity AI's bias towards Indian news sites,Usage of AI models and search results accuracy,General queries about Perplexity AI's mobile app features
- Perplexity AI search engine issues & updates: Users expressed frustration about Perplexity AI's search functionalities, including difficulties in changing sources mid-search and the use of non-academic sources even in academic mode (example link). They highlighted discrepancies between Perplexity and other platforms like Morphic.sh in terms of source reliability.
- Discussions mentioned the frequent appearance of Indian news sites and LinkedIn in search results, which some users found biased and annoying. Members suggested that the search engine might use user location or profile settings to determine search result prioritization.
- Claude's token limitations on Perplexity AI: Users discussed that Claude on Perplexity AI doesn’t provide the full 200k tokens and is limited to approximately 32k tokens. This restriction dissuaded some users from purchasing a subscription.
- The conversation highlighted dissatisfaction with the token limits, comparing Perplexity AI as more of a search engine than an actual assistant.
- Generating graphs/visualizations using Perplexity: Members questioned how to generate graphs and visualizations within Perplexity, with responses clarifying that it can generate code for platforms like Google Colab but lacks built-in support (example link). The community suggested using external tools or integrations like Mermaid for diagrams.
- Discussions included guidelines on using code blocks and userscripts to render diagrams automatically, noting that AIlin or Complexity extensions might offer integrated support.
- Referral links and promotional codes for Perplexity AI: Users frequently shared referral links and promotional codes to help others get discounts on Perplexity AI subscriptions (example link). A common sentiment was the anticipation and demand for a trial version.
- Some regretted that a trial version isn't available due to past misuse by hackers, which restricted the service.
- Perplexity AI's mobile app features and crashes: Queries about the availability of new features such as Wolfram Alpha and code generation on Perplexity's mobile app were common. Some users reported experiencing crashes, particularly when performing pro searches on iPhone.
- Discussions also involved feedback on the performance and comparison of AI models on mobile versus the web app, with some users expressing preferences for writing modes and search methods.
Links mentioned:
Perplexity AI ▷ #sharing (9 messages🔥):
Best use cases for Perplexity AI,Rubik's Cube 50th anniversary,EU charges Meta,Electric flights development,AI video advances,Starting a business with Perplexity,Emotional impact of tears,Microsoft Connect Test search
- Rubik's Cube Celebrates 50 Years: The Rubik's Cube turns 50, marking five decades of popularity for the classic puzzle toy. Watch the celebration video here.
- The video also covers other significant news including the EU charging Meta and advancements in electric flights. *
- Writing Business Plans with Perplexity: Learn how to create a comprehensive business plan using Perplexity AI's platform. This guide provides detailed steps to produce an effective business strategy.
- The lean canvas technique for startups is discussed in-depth, emphasizing its usefulness. Watch the detailed guide here: Lean Canvas Guide.
- Exploring Best Use Cases for Perplexity AI: Discover the most effective use cases for Perplexity AI through this search link: Best Use Cases. It highlights optimal applications to maximize AI functionality.
- The discussion features various industries, including healthcare and finance, where Perplexity AI has shown promising results.
Link mentioned: YouTube: no description found
Perplexity AI ▷ #pplx-api (8 messages🔥):
API settings loading issue,Perplexity citations request follow-up,Sonnet 3.5 and Perplexity API usage,API model availability,Search engine via API
- API settings loading in Chrome: A user reported issues accessing the API settings on Chrome, with the page loading indefinitely. Switching to Safari resolved the issue, and clearing the cache was suggested.
- "Seems to be working fine. Have you tried it in another browser?" another user responded. The issue was resolved by trying a different browser and clearing the cache.
- Perplexity citations request follow-up: A user inquired about the status of their Perplexity citations request submitted two weeks prior. Another user echoed the same concern and mentioned sending a follow-up email to api@perplexity.ai.
- The users are eagerly awaiting a response for beta API access, with one stating "Haven't heard anything. I followed up with an email to api@perplexity.ai earlier this week."
- Sonnet 3.5 not available via Perplexity API: A user asked about using Sonnet 3.5 with the Perplexity API. It was clarified that Sonnet is not available via the API, and a list of available models was provided.
- The list and details of the available models were shared, mentioning matching the Hugging Face implementation where possible. "Sonnet is not provided via our API" was highlighted.
- Interest in using the search engine via API: Another user expressed interest in using the search engine through the API after learning Sonnet was unavailable.
- "Mhh okay I would love to use the search engine via api" the user replied, indicating their continued interest despite the initial limitation.
Link mentioned: Supported Models: no description found
Unsloth AI (Daniel Han) ▷ #general (130 messages🔥🔥):
Scaling synthetic data creation,Issues with Unsloth on multi-GPU setups,Unsloth's compatibility with Ollama,Unsloth's new features and updates,Use of RAG (Retrieval-Augmented Generation) with Unsloth
- Scaling Synthetic Data with 1 Billion Personas: Aran Komatsuzaki shared about Persona Hub, a collection of 1 billion diverse personas that resulted in massive gains on MATH from 49.6 to 64.9. It is presented as a proof of concept in a GitHub repository and discussed further in an arXiv paper.
- A member commented that the project is similar to augmentoolkit but with much fewer personas than the 1 billion used by Persona Hub. Another member expressed an intention to read the paper for more insights.
- Unsloth Issues on Multi-GPU Setups: Multiple users experienced difficulties running Unsloth on multi-GPU setups, encountering various runtime errors, such as
subprocess.CalledProcessError. A particular error noted was related to running Unsloth downloads and quantization processes with multiple GPUs.- Unsloth currently doesn't support multi-GPU setups officially, and users are advised to try workarounds, or contact the team for beta versions. One workaround involved using environmental variables, which didn't resolve the issue.
- Unsloth's Integration with Ollama: A user inquired about integrating Unsloth with Ollama, to which another user confirmed they are separate but can work together with some setup. Unsloth can convert trained models to be used seamlessly with Ollama.
- The conversation highlighted the complexity of automating the compatibility pipeline due to the way models are built. A guide for integrating Unsloth models into Ollama is being prepared.
- Unsloth Features & Recent Updates: Unsloth has been praised for its efficiency in fine-tuning and new features like Gemma 27B with non-extended context size and recent updates to Phi-3 Mini. Users report using Unsloth to fine-tune models for specific tasks with remarkable accuracy.
- Discussions included the potential for Unsloth to improve extensive data tasks efficiently. Particularly, one user achieved over 95% accuracy in radiology-related data extraction, showing Unsloth's capabilities in achieving beyond state-of-the-art results.
- Integrating RAG with Unsloth: Microsoft's GraphRAG system was introduced as a potential tool for integrating with Unsloth to boost retrieval-augmented generation capabilities. The idea was well received with interests in possible integration.
- The conversation concluded with curiosity about how Unsloth could benefit from integrating RAG. The integration would allow users to perform fine-tuning along with retrieval-augmented generation.
Links mentioned:
Unsloth AI (Daniel Han) ▷ #off-topic (6 messages):
Microsoft updated Phi-3 Mini,New recipe training suspicion,Antropic's steering stuff and Sonnet 3.5,OpenAI develops CriticGPT
- Microsoft updates Phi-3 Mini, boosts performance: Microsoft released updates to the Phi-3 Mini model, specifically enhancing 4K and 128K context model checkpoints. Links to the new models can be found on Hugging Face for 4K and Hugging Face for 128K.
- One user speculated that recent massive score improvements might be due to an undisclosed training method similar to techniques used by Antrophic and OpenAI (e.g., steering and CriticGPT). “The score is basically jumped” sums up the users' excitement.
- Community reacts to unexpected model upgrades: Users on the LocalLLaMA subreddit expressed surprise and enthusiasm over the Phi-3 Mini update. The original post linked to Reddit, describing the nature of these updates.
- One user humorously referred to OpenAI as “ClosedAI’s CriticGPT”, highlighting the community's engagement and liveliness.
Link mentioned: Reddit - Dive into anything: no description found
Unsloth AI (Daniel Han) ▷ #help (44 messages🔥):
SPPO support for Unsloth,Common errors with xformers and PyTorch,Fine-tuning models with Unsloth and deploying on Ollama,Running Unsloth models on AMD GPUs,Handling Out of Memory (OOM) errors during model training
- SPPO works with Unsloth: theyruinedelise confirmed that if SPPO works on TRL, it works with Unsloth.
- theyruinedelise reiterated that Unsloth's compatibility extends to SPPO via TRL, making it a functional integration.
- Xformers Error with PyTorch 2.2: A user encountered an IndexError related to xformers and PyTorch 2.2 during Unsloth usage.
- unclemusclez mentioned troubleshooting this issue and pointed towards potential incompatibility with nightly versions of PyTorch.
- Deploying Fine-tuned Models on Ollama: ozzy.khal faced issues running a fine-tuned model locally on CPU, with an attribute error in the Unsloth framework.
- edd0302 suggested using Ollama which runs on CPU and provided a Colab notebook link to facilitate this.
- Running Unsloth on AMD GPUs: unclemusclez shared difficulties in running Unsloth on AMD GPUs and mentioned the need to compile from source.
- theyruinedelise acknowledged the challenge, attributing it to potential incompatibility and instability with nightly builds of PyTorch.
- Handling OutOfMemory Errors on T4 GPU: tom250 raised concerns about encountering an OOM error while fine-tuning Qwen2-0.5B on a T4 GPU.
- The error indicated insufficient memory, with tom250 citing specific PyTorch memory statistics and recommended environment variables.
Links mentioned:
Unsloth AI (Daniel Han) ▷ #showcase (2 messages):
llmcord.py,Discord LLM frontend,jakobdylanc's GitHub project,community feedback on llmcord.py
- Discord as an LLM Frontend with llmcord.py: jakobdylanc introduced a new script called llmcord.py that transforms Discord into a frontend for LLMs. This tool is designed to be simple and robust, allowing users to interact with LLMs directly on Discord.
- A community member praised the project saying, 'Nice great job!' indicating positive reception and interest from the community.
- Community Praise for llmcord.py: theyruinedelise expressed their appreciation for the project by saying, 'Nice great job!' This shows a positive reception from the community towards jakobdylanc's initiative.
- Such feedback highlights the collaborative and supportive nature of the community surrounding Discord and LLM integrations.
Link mentioned: GitHub - jakobdylanc/discord-llm-chatbot: llmcord.py • Talk to LLMs with your friends!: llmcord.py • Talk to LLMs with your friends! Contribute to jakobdylanc/discord-llm-chatbot development by creating an account on GitHub.
Unsloth AI (Daniel Han) ▷ #community-collaboration (2 messages):
collaborative tutorial and notebook release,dataset support enhancements,finetuning guide available,requests for feedback on colab notebook
- Collaborative Tutorial Release: A member shared a new Colab notebook that supports multiple datasets and various prompt formats. This notebook has not been thoroughly tested and they are seeking feedback.
- Key features include Exllama2 quant support for Kaggle users, automatic scaling of LoRA ranks, and a general finetuning guide with additional tips. They specifically asked for opinions from individuals tagged in the discussion.
- Requests for Feedback on Colab Notebook: The member who shared the Colab notebook requested feedback from others in the community, particularly tagging two individuals. They seek insights and suggestions to improve the notebook's functionality and fix any potential issues.
- Immediate responses or insights were not recorded, highlighting the anticipation for detailed reviews and comments. The deployment focuses on enhancing dataset support and fine-tuning methodologies.
Link mentioned: Google Colab: no description found
Unsloth AI (Daniel Han) ▷ #research (11 messages🔥):
Scaling Synthetic Data Creation with 1,000,000,000 Personas,Persona-driven data synthesis methodology,Google released Gemma 2,Generalized Knowledge Distillation (GKD) by Google DeepMind
- Scaling Synthetic Data Creation with 1,000,000,000 Personas: A tweet presents a collection of 1 billion diverse personas automatically curated from web data, showcasing massive gains on MATH: 49.6 -> 64.9. Relevant links include the GitHub repo and the Arxiv paper.
- Members discussed the importance of data over the code, with one noting 'the data is way more important than the code' while others mentioned the ease of replication.
- Gemma 2: Google's Latest Open LLM Release: Google released Gemma 2 with 4 open-weight models available on the Hub. The models are integrated with Hugging Face Transformers and Google Cloud & Inference Endpoints.
- Members expressed excitement about the collaboration with Google to ensure best integration in the Hugging Face ecosystem.
- Generalized Knowledge Distillation (GKD) by Google DeepMind: Google DeepMind's paper on Generalized Knowledge Distillation (GKD) addresses 'distribution mismatch' in auto-regressive sequence models by training the student on its self-generated output sequences. This approach offers flexibility to employ alternative loss functions between the student and teacher.
- A member highlighted how GKD fixes the issue where the student model's output during training differs during inference.
Links mentioned:
Stability.ai (Stable Diffusion) ▷ #general-chat (155 messages🔥🔥):
Running Stable Diffusion with limited VRAM,Issues with Stable Diffusion 3,Training LoRA (Low-Rank Adaptation) for specific styles,Stable Diffusion for different image styles,Anti-AI art software potential
- Running Stable Diffusion with limited VRAM: A member asked about running Stable Diffusion locally with 12GB VRAM, mentioning challenges with everydream2 trainer requiring 16GB VRAM. Another user shared their experience of generating a tiny checkpoint on an 8GB system that took 4 hours.
- The discussion emphasized the hardware requirements for running Stable Diffusion, with members recommending trying different models or setups despite VRAM limitations.
- Issues with Stable Diffusion 3: Members discussed the shortcomings of Stable Diffusion 3 (SD3), noting it misses certain fine-tuning aspects and has incomplete features. One user highlighted the lack of an easy way to train LoRA efficiently on it.
- A member expressed frustration about limitations in image quality, especially in more complex scenes like lying or sitting positions, and mentioned the priority for more advanced features.
- Training LoRA for specific styles: Users shared the desire to train LoRA models for specific needs, such as including 3D fractals or game screencaps. One member pointed out that Stable Diffusion 3 doesn't easily support LoRA training.
- Despite the hurdles, community members offered advice on using various tools and resources to achieve specialized training, emphasizing the frequent need for experimentation.
- Stable Diffusion for different image styles: Several users exchanged experiences about Stable Diffusion's strengths in diverse image styles, including line art, cartoon, anime, horror, portraits, nature shots, and more. Some detailed specific use cases like combining certain styles to enhance model capabilities.
- A user humorously noted the uncertainty of experimenting with different prompts and the variety of outcomes, highlighting the versatility of the tool with creative usage.
- Anti-AI art software potential: Discussion revolved around the idea of creating software to protect artist work from being used in AI-generated models, akin to Glaze and Nightshade. The consensus was that such measures are currently ineffective due to existing workarounds.
- Members debated the feasibility of anti-AI encoding in artworks, considering practical limitations and potential countermeasures, while some pointed out the moral implications and the reality of digital content's replicability.
Links mentioned:
OpenAI ▷ #ai-discussions (118 messages🔥🔥):
High cost and performance of AI hardware (H100 and H200 GPUs, Google TPUs),Disappointment with AI image generation tools (Luma Dream Machine, Runway Gen-3),Potential of using TPU V3-8 and Paperspace for AI training,Multimodal models and their limitations in specific domains,Orchestrators like LangChain and context limits in AI
- AI Hardware Costs Spark Controversy: Discussions revolved around the high cost of acquiring 8 H100 GPUs, with costs cited at upwards of $500k and the difficulty of obtaining them directly from NVIDIA without an enterprise account.
- Members explored alternatives like Google TPUs and rental services like Paperspace to mitigate high costs, noting significant price differences and varying levels of performance.
- User Dissatisfaction with AI Image Generators: Users expressed disappointment with AI image generation tools such as Luma Dream Machine and Runway Gen-3, describing them as overhyped and overpriced.
- One user noted that $15 only grants 6-7 generations on Runway Gen-3, with performance not substantially better than Luma Dream Machine, leading to quick disinterest.
- Exploring TPU and Cloud-Based Training: Conversation highlighted the potential of using Google TPU V3-8 as a viable alternative to H100 GPUs for training large models, albeit at a slower pace.
- Services like Paperspace were recommended for renting powerful GPUs at hourly rates, with H100s available for $2.24 an hour, offering a cost-effective solution.
- Debate Over Multimodal Model Efficacy: The discussion acknowledged that while multimodal/general models offer impressive versatility, they currently face technical limitations.
- Specific models tuned for specialized tasks (e.g., coding) were deemed more effective, particularly for languages like Python, though challenges persist for more complex or varied tasks.
- Chat on Orchestrators and AI Context Limits: Questions were raised about the future potential of AI context limits exceeding the current 4k tokens in OpenAI's API, highlighting a need for improvement.
- Members also discussed orchestrators like LangChain and shared experiences integrating or replacing models such as GPT-4 and LLama within their prompt-engineered systems.
OpenAI ▷ #prompt-engineering (3 messages):
Ensuring GPT completes all steps in task,Prompt design for intention checking in RAG on GPT-4o,Issues with GPT skipping steps in multi-step prompt
- Customer-GPT Skips Steps: A member asked how to ensure their Customer-GPT rechecks itself after completing a task, noting it skips steps despite a logically laid out prompt.
- Solbus suggested structuring instructions with a "this comes before that" approach to help the model avoid skipped instructions by continuing from where it left off if context limits are reached.
- Intention Checking Prompt for RAG: Another member sought advice on creating an intention checking prompt for RAG on GPT-4o, categorizing input into three categories: ambiguous, history-based, or requiring a new VectorDB search.
- They reported consistency issues, where the bot mixed up questions with history and initiated unnecessary searches, and asked if others had reliable prompt designs.
OpenAI ▷ #api-discussions (3 messages):
Customer-GPT checking itself after task completion,Intention checking prompt for RAG on GPT-4,Structuring GPT instructions to avoid skipping steps
- Customer-GPT: Ensure thorough task completion: allenamenwarenschonvergeben seeks advice on making Customer-GPT recheck steps after task completion. The issue involves GPT skipping steps despite a logical prompt layout, and they prefer automated checks over manual prompts.
- solbus suggested structuring instructions in a 'this comes before that' order to ensure the model follows each step sequentially, potentially addressing skipped instructions by making the steps dependent on previous ones.
- Reliable prompt crafting for intention checking in RAG on GPT-4: tvl4121 is facing challenges creating a prompt for GPT-4 to categorize user input into three categories: ambiguous, answerable with conversation history, or requires VectorDB search. They report inconsistent results, especially with context-change questions.
- No direct solutions were provided, but the query highlights the demand for more reliable methods to handle context and intention checking in RAG applications.
Eleuther ▷ #general (20 messages🔥):
vLLM Deployment,Probing Learnt Representations in Diffusion Models,GPT-4 Parameter Count and Mixture of Experts
- vLLM solves HF issue: A user noted a known issue with HF and suggested using vLLM instead, sharing a wiki link for saving models to 16 Bit. Another user confirmed success using vLLM after following the advice.
- The community recognized the utility of vLLM for efficient model deployment, with users expressing gratitude for the guidance provided.
- Diffusion Models and Learnt Representations: A user requested paper recommendations for probing learnt representations in diffusion models, especially for language, and shared a paper link on latent diffusion models containing relevant research. The discussion highlighted the interpretability and internal activations of LDMs.
- The paper points out that LDMs encode linear representations of 3D depth and salient-object distinctions early in the denoising process, which aids in image synthesis and high-level editing.
- Future Model Parameters Speculated: A user inquired whether OpenAI would disclose parameters for future models and why GPT-4's parameters are not available. A rumor mentioned 1.7T parameters for GPT-4, attributed to a mixture of experts.
- Users debated the legitimacy of this figure, citing a supposed Nvidia confirmation during GTC, aligning with the 220B times 8 model size. Others remained skeptical, questioning Nvidia's NDA obligations.
Links mentioned:
Eleuther ▷ #research (73 messages🔥🔥):
Tokenization in LLMs,Factorization Curse in Language Models,Covert Malicious Fine-Tuning,Memory Efficiency in PEFT Methods,Estimating Networking Hardware Costs for ML Clusters
- Tokenization Challenges in LLMs: A new paper discusses how individual tokens in LLMs often lack semantic meaning, such as Llama-2-7b splitting 'northeastern' into unrelated tokens. This study investigates the 'erasure' effect in token representations.
- The community expressed enthusiasm for the research, particularly its insights on converting arbitrary token groups into high-level representations, noting its contribution to understanding tokenization.
- Factorization Curse Hinders Info Retrieval: A recently highlighted paper reframes the 'reversal curse' as a 'factorization curse,' affecting information retrieval due to LLMs failing to learn joint distributions under different factorizations. It introduces WikiReversal to simulate knowledge-intensive tasks.
- Members noted the paper's implication that training with corrupted or paraphrased data can lead to better generalization, emphasizing that 'UL2 styled objectives' might be key.
- Covert Malicious Fine-Tuning Threat: A study presents 'covert malicious fine-tuning,' demonstrating how such methods can compromise model safety while evading detection, with a success rate of 99% in harmful instructions. The findings raise concerns about securing black-box fine-tuning interfaces.
- Community members speculated on the implications, linking it to broader discussions on defense mechanisms and the challenges in safeguarding language models from sophisticated attacks.
- Revolutionizing PEFT Memory Efficiency: A paper investigates the memory inefficiency in Parameter-efficient Fine-Tuning (PEFT) methods, proposing a reversible model approach. This aims to reduce activation memory while maintaining performance.
- Discussion highlighted the difficulty in modifying PLMs to reversible variants and the essential role of preserving the starting point in PEFT methods.
- Estimating Networking Costs for ML Clusters: A draft document shared for feedback aims to estimate networking hardware costs in ML clusters by analyzing components of the H100 SuperPOD. The draft uses retail prices in a detailed spreadsheet.
- Suggestions included consulting with experts like SemiAnalysis for accurate cost estimates, and comparing rental prices of smaller DGX clusters to extrapolate for larger buildouts.
Links mentioned:
Eleuther ▷ #lm-thunderdome (23 messages🔥):
Issues reproducing Gemma 2 metrics withlm_eval, `Possible fixes for Gemma 2 metric reproduction issues`, `Visualization of fewshot prompting and its impact on accuracy`, `Clarification on the evaluation framework and scoring mechanism in `lm_eval,Integration of OpenAI'sevalslibrary withlm_eval``
- Gemma 2 Repro Issues Explained: Users are having trouble reproducing Gemma 2 metrics using
lm_evaland see discrepancies in accuracy benchmarks like piqa as compared to the model card's reported metrics. They've tried using proper versions of transformers and setting dtype to bfloat16 (details).- Community members suggested checking instruction tuning and model-specific token settings like using
add_bos_token=trueto match the results better (discussion).
- Community members suggested checking instruction tuning and model-specific token settings like using
- BOS Token Fix Boosts Gemma 2 Scores: Adding
add_bos_token=truetomodel_argssignificantly improved evaluation metrics for Gemma-2, achieving scores closer to those reported in the Gemma 2 model's paper.- Hailey demonstrated this with clear before-and-after results, where lambada_openai accuracy jumped from 0.2663 to 0.7518.
- Exploring Fewshot Prompting Impacts: Members are seeing negative effects of fewshot prompting on evaluation accuracy and are looking for ways to visualize and inspect these prompts.
- Hailey suggested using
--log_samplesto save and inspect outputs and mentioned that issues with--write_outflag will be reviewed.
- Hailey suggested using
- Framework Mechanics and Documentation: Questions were raised about the evaluation framework mechanics, such as hidden prompting and answer extraction methods in lm_eval.
- Hailey clarified that LLM-as-a-Judge is not used; instead, they rely on predefined prompts and filter steps like regex matching to grade outputs.
- Limited Integration with OpenAI's Evals: A request was made about running OpenAI's
evalslibrary withinlm_eval, but there’s currently no direct integration.- Hailey noted that while integration is possible if licensing permits, it requires additional configurations and doesn't come out of the box.
Links mentioned:
Nous Research AI ▷ #research-papers (3 messages):
Apple's variable bit quantization in on-device LLM,Talaria tool for model visualization and optimization by Apple,Introduction of Apple Foundation Models at WWDC 2024,Introducing Terminator architecture without residuals, dot product attention, or normalization
- Apple's variable bit quantization empowers on-device LLM: Apple utilizes variable bit quantization in their on-device large language models (LLM) to enhance performance. The technique was detailed in their Talaria tool published in April 2024.
- The paper garnered the Best Paper Honorable Mention and involves researchers like Fred Hohman and Chaoqun Wang among others. Since its internal deployment, Talaria saw 800+ practitioners submit over 3,600 models.
- Apple Foundation Models debut at WWDC 2024: At the 2024 Worldwide Developers Conference, Apple unveiled Apple Intelligence, a personal intelligence system integrating iOS 18, iPadOS 18, and macOS Sequoia. The foundation models include a ~3 billion parameter on-device LLM and a server-based model available with Private Cloud Compute.
- These generative models are tailored for everyday tasks like writing, summarizing notifications, and creating playful images, according to Apple's report.
- LeopolisDream teases Terminator architecture debut: @LeopolisDream revealed a new architecture named Terminator via Twitter, as shown here. The architecture notably omits residuals, dot product attention, and normalization.
- This announcement links to a detailed arXiv paper, promising novel approaches in model design and optimization.
Links mentioned:
Nous Research AI ▷ #datasets (1 messages):
PersonaHub introduction and potential use cases,Key considerations for scheduling and logistics for multi-show festivals,Distribution and organization of public services in Halifax,Application of synthetic data in LLM research and development
- PersonaHub scales synthetic data creation with diverse personas: This Hugging Face repo introduces PERSONA HUB, a collection of 1 billion diverse personas for creating synthetic data. The methodology facilitates high-quality data synthesis for various applications, potentially driving a paradigm shift in LLM research and development.
- A novel persona-driven data synthesis methodology leveraging LLM perspectives, allows for versatile, scalable, and flexible data creation. The paper highlights its applications, such as in logical reasoning problems and game NPC creation, demonstrating its profound impact.
- Scheduling logistics for multi-show festivals: Key considerations for scheduling and logistics at performing arts centers like the Broward Center include operational aspects, facilities, and programming management. It’s crucial to coordinate multiple show schedules to ensure seamless transitions and audience management.
- Effective logistics planning should take into account the utilization of various facilities and audience dynamics. Managing multiple shows requires careful coordination to avoid conflicts and bottlenecks in the center’s operations.
Link mentioned: proj-persona/PersonaHub · Datasets at Hugging Face: no description found
Nous Research AI ▷ #off-topic (2 messages):
MatrixBridge AI demo for NotDevin,Hackathon in Italy by Yaya Labs
- MatrixBridge AI launches NotDevin demo: MatrixBridge AI, specializing in enterprise browser agents, launched a demo of their latest agent, NotDevin, showing it could replace Devin with their platform and Google's Project IDX. They encouraged users to sign up for their waitlist to start building NoCode expert browser agents.
- Members are invited to give feedback and are encouraged to reach out for more information, promoting good karma through retweets.
- Hackathon in Italy: Hypersensual Overclocking 2024: Yaya Labs announced a hackathon titled Hypersensual Overclocking 2024: Making Machines Feel in collaboration with Umanesimo Art. Applications for the event in Italy are now open, with a chance to win a residency with Yaya Labs.
- Participants interested in joining can apply through the link in Yaya Labs' bio, engaging in the experience to potentially gain a residency with Yaya Labs.
Links mentioned:
Nous Research AI ▷ #interesting-links (1 messages):
harvie_zhang: https://x.com/leopolisdream/status/1804627325583327358?s=46&t=BsqYoGA8vIHGcXwORlMk7w
Nous Research AI ▷ #general (82 messages🔥🔥):
Animating with Vision Capable Language Models (VLLMs),Runway's High-Fidelity Video Generation,Cost Concerns with Runway's AI Tools,New techniques for VLLMs and multimodal models,Custom quantization schemes for Llama models
- Animating with VLLMs idea sparks debate: A user proposed that Vision Capable Language Models (VLLMs) could be taught to rig and automate basic animations with the right dataset and workflow, sparking a technical discussion. They suggested that the model could program animations and self-correct iteratively, making the animation process more efficient.
- Verafice pointed out a more efficient solution, linking to a diffusion-based keyframe in-betweening method which generates precise and diverse character motions. Teknium and others agreed that Hermes Pro might offer potential here.
- Runway's video generation sparks interest despite cost: Runway's new high-fidelity, controllable video generation tools were shared with excitement in the community, with discussions revolving around its potential. However, the high cost ($12 for 60 seconds) sparked debates on affordability.
- Mautonomy and others criticized the pricing structure, suggesting that 0.5$ per generation would be more reasonable. Some users even compared it to other expensive services like audio transcription.
- vLLMs support and experimentation: Discussions on supporting and experimenting with vision-capable language models (vLLMs) have been active, with some users involved in training and enhancing their functionalities. Notably, Teknium mentioned assisting developers in training vision models and supporting implementations.
- Links and highlights of various efforts and support for tool calling within vLLMs were shared, indicating an ongoing community effort to evolve these models.
- Llama.cpp feature extraction improvements: Feature extraction efforts for Llama models were discussed, particularly the implementation of representation engineering into llama.cpp. Teknium shared a link to a related tweet, highlighting GGUF support.
- Researchers are also working on custom per-layer quantization in llama.cpp, which is seen as a promising advancement for model optimization and efficiency.
- Apple's Talaria tool for on-device ML optimization: Apple's Talaria tool for on-device ML optimization was mentioned, highlighting its focus on model size, latency, and power metrics. The tool visualizes model stats and simulates optimizations.
- Azure2089 referred to a paper detailing Talaria, praising its impact on optimizing and evaluating models on-device. This could be a great addition for open LLMs.
Links mentioned:
Nous Research AI ▷ #ask-about-llms (3 messages):
Creating conversational dataset or instructions dataset from documents,Open-source tools for generating datasets,Anthropic solutions for dataset generation with sufficient budget,Genstruct 7B model for instruction generation from raw text corpus,Inspired by Ada-Instruct model for instruction generation
- Creating conversational datasets from documents: Macacodomato4260 inquired about pointers for creating conversational datasets or instructions datasets from documents. Kainan_e responded by highlighting that it depends on the type of documents and available budget.
- Kainan_e suggested using an open-source tool developed by NousResearch or leveraging Anthropic's tools with appropriate prompting and budget (Genstruct 7B, Ada-Instruct).
- Genstruct 7B: A tool for dataset generation: Kainan_e shared a link to Genstruct 7B, an instruction-generation model by NousResearch. This model is designed to create valid instructions from a raw text corpus to facilitate the generation of synthetic instruction finetuning datasets.
- The development of Genstruct 7B was inspired by Ada-Instruct, which trained a custom instruction-generation model. He noted that previous methods primarily relied on in-context approaches.
Link mentioned: NousResearch/Genstruct-7B · Hugging Face: no description found
Nous Research AI ▷ #world-sim (4 messages):
Sharpening bots into question/answer bots linking to Nous,Fixed issue by apyh,User appreciation for AI scenarios,Teknium's future possibilities for bots
- Sharpening bots into Q/A tools: A user inquired about sharpening the bots into question/answer bots that link to various Nous-related areas. This would leverage everything available from Nous for streamlined information.
- Another user confirmed that one day this will be possible, hinting at future enhancements in bot capability within the community.
- Fix implemented by apyh: A user named apyh mentioned fixing an issue, stating confidently that it should work fine now. No specifics about the issue were provided.
- Super cool AI appreciation was expressed by another user, who started new scenarios and found excitement in the capabilities of the AI.
Modular (Mojo 🔥) ▷ #general (5 messages):
Running Mojo on Ubuntu 24.04 on Raspberry Pi 5,Link to AI engineer world fair talk,Importing .mojopkg from a subdirectory
- AI Engineer World Fair Talk Timestamp Request: A user asked for a link to the AI engineer world fair talk and another user provided a YouTube video link along with timestamps.
- The user mentioned there were several 8-hour long videos and was unsure which one contained the relevant talk.
- Running Mojo on Raspberry Pi 5: A user mentioned an issue running Mojo on Ubuntu 24.04 on a Raspberry Pi 5 and was looking for assistance.
- The message did not contain further discussion or resolution on the issue.
- Importing .mojopkg from Subdirectory: A user asked if it's possible to put a .mojopkg in a subdirectory and import from it.
- The message did not receive any responses or solutions.
Link mentioned: AI Engineer World’s Fair 2024 - Keynotes & Multimodality track: https://twitter.com/aidotengineer1. Opening music - 00:002. Announcement - 03:263. AI Engineer Summit Opening Remarks - 17:124. Benjamin Presentation - 17:22...
Modular (Mojo 🔥) ▷ #💬︱twitter (1 messages):
ModularBot: From Modular: https://twitter.com/Modular/status/1808228006068212110
Modular (Mojo 🔥) ▷ #ai (2 messages):
Mojo promising areas,Model and simulator-based RL for LLM agents,Symbolic reasoning and inference time search,Sub-symbolic model steering,Constrained inference
- Mojo promising for various applications: Mojo shows promise in areas beyond just tweaking attention and scaling, such as Model and simulator-based RL for LLM agents, symbolic reasoning, inference time search like MCTS, and sub-symbolic model steering.
- Is anyone working on these applications in Mojo? The user would love to connect with others exploring these areas.
- Discussion on constrained inference: Constrained inference methods like guidance, outlines, or sglang also seem promising within the context of Mojo.
- Mojo could be a robust tool for exploring these constrained inference methods as well.
Modular (Mojo 🔥) ▷ #🔥mojo (27 messages🔥):
Mojo lifetime parameters,Using MutableLifetime and AnyLifetime in Mojo,Package manager necessity for Mojo,Difference between parallelize and sync_parallelize in Mojo,Working with List in Mojo and printing its elements
- Mojo Lifetime Parameters: MutableLifetime and AnyLifetime: A discussion began with a user struggling to implement lifetimes in Mojo, mentioning MutableLifetime as a parameter. Another member suggested using AnyLifetime for generic mutability, and provided a working example involving UnsafePointer and mlir_attr.
- Quotes included mentions of different behaviors on stable and nightly builds, and how lifetimes relate to reference casting. The discussion concluded with a working solution for the stable version.
- Mojo Package Manager Demand: Members voiced the need for a package manager to handle growing community projects and dependencies in Mojo. They discussed past mentions of unofficial package manager efforts.
- The consensus was that an official package manager would be highly beneficial for those dealing with external packages and community contributions.
- Parallelization in Mojo: parallelize vs sync_parallelize: A user asked about the difference between
parallelizeandsync_parallelizein Mojo, with concerns about a runtime warning inparallelize. They sought advice on which function should be used in kernel contexts.- The conversation included details about local runtime creation and destruction warnings and implied that
sync_parallelizemight not have the same caution but didn’t conclude definitively.
- The conversation included details about local runtime creation and destruction warnings and implied that
- Handling Lists in Mojo: A user struggled with appending and printing items in a List in Mojo, pointing out an issue with direct printability. Other members explained that List lacks the Stringable trait and suggested using dereferencing with
[]for iteration and printing purposes.- Additionally, there was a pointer to the Mojo standard library's GitHub for more details on trait implementations and data type handling.
Links mentioned:
Modular (Mojo 🔥) ▷ #nightly (7 messages):
Mojo compiler nightly update,Discussion on stdlib contributors and Mojo merch,Issues with nightly/max package updates,CI transitions and resulting issues
- New Mojo compiler nightly update released: A new nightly Mojo compiler version 2024.7.205 has been released; you can update using
modular update nightly/mojo. The changelog and raw diff are available online.- Community members expressed excitement about the update, while some others encountered issues with package updates.
- Reach out for Mojo merch: A user inquired about whom to contact for Mojo merchandise as a stdlib contributor. Jack Clayton responded confirming he would reach out via DM.
- Glad to see you hang out for them! Should be fixed soon, commented Jack Clayton, addressing package update issues.
- Nightly/max package update issues persist: A member reported no updates available for the
nightly/maxpackage despite the new release. The user decided to revert tomodular update nightly/mojoin the meantime.- Jack Clayton acknowledged the issue, explaining that further problems arose after the initial fix and should be resolved in the next update due to CI transitions.
Modular (Mojo 🔥) ▷ #mojo-marathons (44 messages🔥):
Discussion aboutsrc/maincompilation issues,Benchmarking failing due to rounding errors,System specs provided for troubleshooting,Benchmarking improvements discussion,Tests and benchmarking framework updated,Discussion on data types for matrix multiplication,Brainstorming about improving matrix multiplication algorithms
- Compilation issues in
src/mainflagged: A user reported compilation errors when trying to runmojo main.mojo, with specific errors related toDTypePointerattributes inmatrix.mojo.- A suggested fix was to build with the latest stable version instead of nightly.
- Benchmarking fails due to rounding errors: A member experienced issues with benchmarking, where the functions produced slightly different results leading to assertion failures.
- The fix was pushed to GitHub and resolved the issues, although some users then faced infinite loops during GFlops/s benchmarking.
- Improved benchmarking framework: Thanks to contributions from the community, the testing and benchmarking framework was updated to better measure performance across all data types and sizes.
- These updates encourage participants to update their branches to ensure compatibility.
- Types for matrix multiplication discussed: There was a debate about using
DType.float16for matrix multiplication benchmarking as it might not be the most common data type.- The system will test various types, including
uint/int/floatwith different sizes (8/16/32/64).
- The system will test various types, including
- Brainstorming matrix multiplication improvements: Participants shared ideas for optimizing matrix multiplication, including vectorization, unrolling, and tiling techniques.
- The potential of combining different algorithms like Strassen and Winograd-Copper with zero padding logic was also discussed.
Links mentioned:
OpenRouter (Alex Atallah) ▷ #announcements (1 messages):
Big update to the /models page,Changing Google Token Sizes for Gemini and PaLM models,Deprecation of Default Model setting,Deprecation of custom auth headers for OpenAI API keys
- Big Update to /models Page: A big update to the /models page is coming soon. A sneak peek was shared, and feedback is encouraged in the designated feedback channel.
- Let us know what you'd like to see.
- Token Sizes Changing for Google Models: Gemini and PaLM models will be moving to GPT-equivalent token lengths to make their statistics more standard, resulting in a price increase and a decrease in context limits.
- This will make it the same model and API but with different token sizes and pricing.
- Default Model Setting Deprecation: The Default Model setting on the /settings page is now in the deprecation queue.
- Feedback is requested if you have a valid use for it, as most apps are setting models individually or using auto router.
- Deprecation of Custom Auth Headers: The use of custom auth headers to send OpenAI API keys is being deprecated.
- A better solution will replace it soon; it was used by a few requests in mid-June but has never been officially documented.
OpenRouter (Alex Atallah) ▷ #app-showcase (1 messages):
lastrosade: I made a quick and dirty wrapper if anyone wants it.
OpenRouter (Alex Atallah) ▷ #general (68 messages🔥🔥):
Mistral API error handling,Differences between LiteLLM and OpenRouter,Improving efficiency in conversation bots,Claude 3.5 intermittent errors,Frontend Apps for OpenRouter on iOS
- Troubleshooting Mistral API Errors: Members discussed receiving Mistral API errors when using OpenRouter with Sonnet 3.5, despite not directly using Mistral. Possible fallback to Mistral when the main model request fails seems to be the issue, as explained.
- It was noted that errors result from the inference provider's backend, not OpenRouter itself. A recommendation was made to contact Aider’s support to verify why the fallback occurs.
- LiteLLM vs. OpenRouter: Members questioned the differences between LiteLLM and OpenRouter, learning that LiteLLM is essentially software while OpenRouter is an online API service. Explanation clarified that OpenRouter forwards messages from the provider verbatim.
- Discussion highlighted OpenRouter's role as an intermediary, with users needing to set preferences to avoid fallback to unwanted models.
- Enhancing Discord Bot Conversations: A discussion focused on making Discord bots using OpenRouter more efficient by appending only relevant parts of messages to prompts, thus saving tokens. It's verified that saving the entire conversation elsewhere and including just essential snippets is common practice.
- Using efficient prompt management strategies is vital for long conversations due to the limited context size models available, as discussed by SillyTavern Discord users.
- Handling Claude 3.5 Errors: Members reported intermittent 500 errors with the Claude 3.5 model, affecting both self-moderated and generally moderated versions. Claude 3.0 continued to work without issues.
- The errors appeared to be model-specific glitches rather than broader infrastructure issues. It was suggested that fixes are underway.
- Finding Suitable iOS Apps for OpenRouter: Queries about iOS apps that support OpenRouter led to recommendations for Pal Chat and Typingmind. Both apps reportedly fixed prior bugs related to OpenRouter and now support a variety of APIs.
- The community also discussed other frontends like LibreChat and SillyTavern, even though some users expressed dissatisfaction with roleplay-focused interfaces.
Links mentioned:
OpenAccess AI Collective (axolotl) ▷ #general (49 messages🔥):
Instruction-tuned models discussion,Downsides of continuing training IT over base model,Plans to add CAME or Adam-mini optimizers to axolotl,High grad_norm values while fine-tuning gemma 27b,Prioritizing accuracy in numerical answers over explanatory text
- Instruction-tuned models spark debate: A member discussed the usage of the instruction-tuned (IT) version for models, noting the potential benefits of using IT out of the box or fine-tuning it further. Another member responded that it might be easier to uncensor a pre-trained model and harder to change its style with a finetune of the IT.
- Members added insights about open IT datasets, suggesting they usually underperform compared to proprietary ITs, influencing the training approach.
- Interest in CAME and Adam-mini optimizers: A member inquired about the addition of CAME or Adam-mini optimizers to the axolotl project, highlighting their memory-saving benefits. They shared papers on CAME (arxiv.org/abs/2307.02047) and Adam-mini (arxiv.org/pdf/2406.16793).
- It was noted that CAME provides training stability and performance while Adam-mini can perform on par or better than AdamW with less memory footprint.
- High grad_norm issues in finetuning Gemma 27b: A member reported seeing massive grad_norm values when trying to finetune Gemma 27b, whereas the 9b model did not have such issues. Another member suggested using lower learning rates and flash attention due to the model's softcap constraints.
- Gemma was described as being a pain to train, with overfitting issues and comparisons drawn to difficulties with training Llama3.
- Weighted cross-entropy for priority in responses: A member working on a project wanted to emphasize numerical answers over explanatory text in model outputs and shared an example of a structured prompt using weights. They were seeking research in this area but could not find relevant papers or information.
- Upon noticing a section on weighted cross-entropy in the trainer, they decided to explore that approach further.
- Difficulty generating accepted/rejected pairs in ORPO: A member asked if ORPO requires strictly accepted-rejected pairs for every row in training data and expressed difficulty generating these pairs. Another member confirmed that both are required and mentioned that is how the reward is calculated in ORPO.
- This means generating accepted/rejected pairs is crucial for ORPO's preference alignment, making the process tricky for some users.
Links mentioned:
OpenAccess AI Collective (axolotl) ▷ #general-help (3 messages):
Error message investigation,Configuration issues
- Nanobitz requests log details for error investigation: Nanobitz requested a bit more log details to determine the cause of an issue in their setup. The request indicates a need for deeper error analysis.
- Could you provide a bit more logs to determine which step caused this?
- Louist4455 shares complete error message details: Louist4455 shared the full error message in response to the previous request for more information. This was intended to help with the troubleshooting process.
- Here is the full error message:
OpenAccess AI Collective (axolotl) ▷ #axolotl-help-bot (13 messages🔥):
Training Gemma2 models with eager attention,Modifying YAML for Gemma2 eager attention,Does batch size increase with more GPUs
- Use eager attention for Gemma2 training: An important recommendation suggests using
eagerattention implementation for training Gemma2 models instead offlash_attention_2by setting attn_implementation to 'eager' inAutoModelForCausalLM.from_pretrained('<path-to-checkpoint>').- Significant discussion highlighted the need for this adjustment for better performance, noting that adjusting this parameter can be crucial during training phases.
- Adjust YAML for eager attention in Gemma2: Adjusting the YAML configuration file for using
eagerattention is necessary for Gemma2 models by addingattn_implementation: 'eager'under model loading parameters.- A detailed explanation provided steps to modify the YAML file, simplifying the process for users struggling with implementation.
- GPU count and training batch size correlation: Increasing the number of GPUs effectively increases the training batch size, as it multiplies the per-device batch size by the number of GPUs.
- The framework automatically handles data division across multiple GPUs, ensuring efficient and parallel processing to leverage hardware fully.
Links mentioned:
LlamaIndex ▷ #blog (2 messages):
Translation of Python multi-agent systems into microservices,Comprehensive video tutorial on 'llama-agents' framework,Building better knowledge assistants beyond naive RAG,Components of advanced data and retrieval modules for knowledge assistants
- Comprehensive guide to translating Python systems into microservices: @MervinPraison created a detailed video tutorial on the new
llama-agentsframework, covering high-level concepts and practical aspects. Check out the full video tutorial for a step-by-step guide.- Described as the most comprehensive tutorial to date, it extends beyond basics to include crucial details and advanced features. A member highlighted, 'Most comprehensive video we've seen so far on
llama-agentsframework.'
- Described as the most comprehensive tutorial to date, it extends beyond basics to include crucial details and advanced features. A member highlighted, 'Most comprehensive video we've seen so far on
- Building superior knowledge assistants with advanced modules: At the @aiDotEngineer World Fair, the discussion focused on improving knowledge assistants beyond naive RAG, emphasizing advanced data and retrieval capabilities. The three main components include innovative data modules that enhance performance.
- The community discussed the essential elements required for the future of knowledge assistants, underscoring the importance of sophistication in data handling. One member stated, 'Building a better knowledge assistant requires advanced data and retrieval modules.'
LlamaIndex ▷ #general (43 messages🔥):
sub-agents tutorials and applications,new agents release,integrating custom message queues,RAG-based chatbots for company data,conversation history in LlamaIndex,issues with building llama-cpp-python,Microsoft’s graph RAG architecture,DocumentSummaryIndex metadata issues with Pinecone
- Sub-agents Tutorials and Applications: A member asked for good tutorials or uses of sub-agents and was referred to
llama-agents. Others expressed excitement about spinning it up.- Discussion mentioned integrating RabbitMQ and the potential for Kafka as custom message queues for inter-agent communication. One quote mentioned 'code abstraction once fully added may help you to setup any message queue'.
- Microsoft’s Graph RAG Architecture Released: A community member shared a link to Microsoft's new Graph RAG Architecture, describing it as a modular graph-based Retrieval-Augmented Generation (RAG) system.
- The release sparked curiosity and anticipation among members, with one mentioning that they 'would love to hear community thoughts' on the new architecture.
- DocumentSummaryIndex Metadata Issues with Pinecone: A member faced issues with DocumentSummaryIndex metadata exceeding Pinecone limits, proposing code changes to exclude excess metadata keys.
- Others suggested alternatives to Pinecone and discussed potential fixes, such as removing metadata for
_node_contentand adding it later, highlighting Pinecone's limitations.
- Others suggested alternatives to Pinecone and discussed potential fixes, such as removing metadata for
- Building a RAG-based Chatbot for Company Data: A query was posted about building a RAG-based chatbot using multiple SQL and NoSQL databases with LlamaHub's different database readers.
- Issues included forming appropriate queries from user text and routing them to the correct database, with community members offering insights and thoughts.
- Issues with Building llama-cpp-python Wheel: A user encountered failures while building a wheel for llama-cpp-python on Google Colab, with errors indicating subprocess issues.
- A community member suggested checking the error messages further up for clues, implying that the issue lies within the subprocess, not
pipitself.
- A community member suggested checking the error messages further up for clues, implying that the issue lies within the subprocess, not
Links mentioned:
tinygrad (George Hotz) ▷ #general (9 messages🔥):
graph rewrite followup and speedup/different algorithm,special dtype 'image dtype',error messages and dev tooling in Tinygrad,PR with a failing test and minimal repro
- Graph Rewrite Under Discussion: Members discussed the
graph rewrite followup, speedup / different algorithmagenda item; no specific graph algorithm was ready to be bet on yet. Egraphs/muGraphs deprioritized for later, focusing on moving more algorithms like the scheduler into graph rewrite.- One member highlighted that rules are not Turing complete thus easy to reason. Another member mentioned they are not ready to bet on a specific algorithm yet.
- Image Dtype Debated: A question was raised about the significance of the special 'image dtype' in the source code, given its widespread 'special treatment'. No challenges or attempts to remove it were specifically mentioned.
- Did you try to remove it? was the main question discussed, though no detailed follow up from other members was recorded.
- Tinygrad Error Message Overhaul Needed: A recurring error in Tinygrad's cstyle.py file triggered discussions about the need for improved error messages and developer tooling before version 1.0. RuntimeError: failed to render UOps.UNMUL was specifically mentioned.
- George Hotz suggested it was more an assert issue, stating that it should never happen. A member agreed and noted they would create a PR with a failing test case.
- PR for Minimal Reproduction Case: A draft PR was initiated to address an error with a maximal reproduction case in Tinygrad. Efforts are ongoing to convert it into a proper minimal reproduction case.
- The plan is to ensure the PR has a failing test of a minimal repro to address the underlying issue cleanly before proper fixes are applied.
tinygrad (George Hotz) ▷ #learn-tinygrad (34 messages🔥):
JIT handling of zero_grad in Tinygrad,Memory issues with gradient accumulation in Tinygrad,Equivalent of torch.no_grad() in Tinygrad,Gradient handling and parameter updates in Tinygrad,Improving documentation and examples for Tinygrad
- JIT handling of zero_grad in Tinygrad: A user questioned how JIT handles
zero_gradin Tinygrad, leading to a clarification that JIT runs the code with the same input/output buffer connections, forcing different computation and connections on the second step. The issue is tracked in tensor.py at 3df47bc.- It was highlighted that zero_grad needs to be called within the JIT function, or the grad buffers remembered from the first macro step could cause issues in subsequent steps.
- Memory issues with gradient accumulation in Tinygrad: Users shared struggles with CUDA memory overflow during gradient accumulation steps in Tinygrad. An approach was suggested to decrement loss by
grad_accum_stepsand update grads in a differentiable way.- One user suggested using
loss.detach()to help with compute graph persistence, while another recommended reassigning gradient memory viaparam.grad.assign(0).realize()within the training step.
- One user suggested using
- Equivalent of torch.no_grad() in Tinygrad: The equivalent to
torch.no_grad()in Tinygrad isTensor.no_grad = Trueor using the@Tensor.inference_mode()decorator. Examples of these approaches can be found here.- A query about operator restrictions highlighted that
a -= lr * a.gradwill assert whilea = a - lr * a.graddoes work, suggesting potential improvements to Tinygrad’s handling of in-place operations.
- A query about operator restrictions highlighted that
- Gradient handling and parameter updates in Tinygrad: Users discussed that
zero_gradonly initializes gradients to zero implicitly at the start but doesn't explicitly zero them out each step. It was noted that withoutzero_grad, gradients would accumulate and can lead to issues.- A user pointed to the need for
realize()on grad parameters within train steps to avoid persistent memory issues, showcasing the complexity of Tinygrad's gradient handling system.
- A user pointed to the need for
- Improving documentation and examples for Tinygrad: There was a call to improve Tinygrad documentation on complex topics like TinyJit and gradient accumulation, as users faced difficulties and inconsistencies. It was suggested to create official examples for these advanced topics to aid understanding.
- Proposals included adding documentation pages specifically for TinyJit along with more detailed examples to better support users in navigating these features.
Links mentioned:
LangChain AI ▷ #general (21 messages🔥):
Best RAG strategy: HydeRetrieval vs. MultiQueryRetrieval,LangChain usage for acknowledging messages,Copilot image storage in Edge,Sharding of embedding databases
- Best RAG strategy for retrieval tasks: A user asked which RAG strategy is better: HydeRetrieval or MultiQueryRetrieval.
- Community members discussed potential issues, with one user encountering empty results using MultiQueryRetrieval in their code.
- How to handle message digressions in LangChain: A question was raised about how to acknowledge input digress messages and proceed with the next AI message using LangChain.
- An example code snippet was provided to demonstrate the invoke method for handling this situation effectively.
- Concerns about image content storage in Edge's Copilot: A user inquired about the storage location and duration of uploaded images in Edge's Copilot.
- The discussion implied concerns over privacy and data handling, but no specific answer was provided.
- Sharding in embedding databases: A user asked if anyone is implementing sharding for embedding databases.
- Responses included one user using serverless MongoDB Atlas, but details on accessing specific shards based on queries were requested.
Link mentioned: Issues · langchain-ai/langchain: 🦜🔗 Build context-aware reasoning applications. Contribute to langchain-ai/langchain development by creating an account on GitHub.
LangChain AI ▷ #langserve (3 messages):
Using FastAPI-Users with LangServe,Allowing file uploads in a LangChain project,Debugging output display issues in CSV playground
- Implementing FastAPI-Users with LangServe: A member asks if anyone uses langserve with fastapi-users for per user logic to secure some endpoints.
- No direct answers or suggestions were provided for this inquiry.
- Enabling CSV File Uploads in askyourcsv Project: A member needs help with enabling users to upload a CSV file directly instead of providing the file path in their askyourcsv project. Their current implementation only allows setting the file path in the code, not uploading.
- They shared code snippets and asked how to modify their FastAPI and LangChain setup to accept file uploads.
- CSV Playground Output Not Displaying: A member reports that there is no output displayed in csv/playground/ despite setting up their FastAPI app and chains correctly.
- They also asked for debugging tips and shared code snippets for their FastAPI server and chain implementation.
LangChain AI ▷ #langchain-templates (12 messages🔥):
Creating a chatbot using LangChain and LangChain Expression Language,Adding action capabilities like scheduling demos and connecting users to sales teams,Defining actions for a chatbot in LangChain,Creating and using Agents in LangChain,Debugging and tracing applications with LangSmith,Providing Python code for LangChain chatbot capabilities
- Building Chatbots with LangChain Basics: A member created a chatbot using LangChain and the LangChain Expression Language, and asked for guidance on adding action features like scheduling demos and connecting users to the sales team.
- Another member provided an overview of using Agents in LangChain, suggesting steps like defining actions and using AgentExecutor, with a note on the importance of debugging with LangSmith.
- Python Guidance for LangChain Actions: A member asked for Python code to add action-taking capabilities to their LangChain chatbot, specifically to perform tasks like scheduling demos and making user-based actions.
- The provided response included steps for defining actions, creating an agent with from_llm_and_tools, using AgentExecutor, and pointed to tutorials for detailed guidance, emphasizing adaptation to specific use cases.
LangChain AI ▷ #share-your-work (4 messages):
Building chatbots using LLM,RAFT pipeline development,Comparison of RAFT and traditional RAG,OpenAI's CriticGPT,Experience sharing and collaboration offers
- Collaborate on LLM Chatbots: Prince from Delhi is offering to collaborate on building chatbots using Large Language Models (LLM). Interested individuals can reach him on WhatsApp here.
- Prince shared his extensive experience in this field and is open to new projects, inviting users to connect for collaboration.
- Implementing RAFT Pipeline: A member inquired about the development of a RAFT pipeline and shared a link to the paper here for further reading. The paper discusses Retrieval Augmented FineTuning (RAFT), a methodology to improve LLM's response by ignoring irrelevant documents.
- The inquiry was made to gather insights and feedback on the performance of RAFT compared to traditional RAG-based approaches.
- OpenAI's CriticGPT Video Review: A user referenced a YouTube video discussing the details of OpenAI's new CriticGPT here, highlighting its purpose to identify and correct errors in GPT-4 outputs. The video reviews the CriticGPT paper and examines its approach to improving code generation accuracy.
- Tried to capture the main details and approach explained in the latest paper from OpenAI on CriticGPT on YT. Would love to hear your feedback.
Links mentioned:
Latent Space ▷ #ai-general-chat (36 messages🔥):
Runway Gen 3 release,Sonnet + Artifacts usage,Anthropic principles of good evals,Chatbot arena ranking issues,Goldman Sachs report on AI investments,Figma AI feature concerns,Best TTS models,Claude 3.5 Sonnet update,Updated Phi-3 Mini by Microsoft,Magic Dev's valuation increase
- Runway Gen 3 impresses with short clips: Runway Gen-3 Alpha Text to Video has been released and is available to everyone, promoting high-fidelity, fast, and controllable video generation. Try it now or see the announcement here.
- A comparison by @amebagpt between Runway Gen-3 and SORA highlights that only Runway Gen-3 is currently available for use. See comparison.
- Sonnet + Artifacts blows minds: The combination of Sonnet and Artifacts is receiving high praise for allowing rapid iteration on process visualizations and diagram manipulations. Users share their productive experiences and mention the potential need for a dedicated AIA session.
- A user described their experience: let's me iterate a visual description of a process I'm trying to flesh out/explore at the speed of thought and no need for manual node adjustment.
- Concerns over Figma AI training data: Figma defended its 'Make Design' feature, clarifying it is not trained on Figma content, community files, or app designs, refuting accusations of data misuse. Read the official remarks here.
- Despite Figma's clarifications, concerns linger in the community about the strong resemblance of the generated designs to existing apps, particularly Apple's Weather app.
- Microsoft boosts Phi-3 Mini capabilities: Microsoft released updates for Phi-3 Mini, improving code understanding in various languages, multi-turn instruction following, and long-context understanding, making it more powerful. The full details can be read here.
- These updates were applied to both the 4K and 128K context model checkpoints, significantly enhancing structured output and reasoning abilities.
- Magic Dev hits $1.5B valuation: Magic Dev, an AI coding startup, is seeking a $1.5 billion valuation in its latest funding round despite having no product or revenue, raising industry eyebrows. Full details available on Reuters.
- The startup, with only 20 employees, suggests the tech investment landscape's current speculative nature, prompting comments on potential market bubbles if not for high-profile backers.
Links mentioned:
Mozilla AI ▷ #llamafile (35 messages🔥):
Hardware requirements for running llama.cpp,Release of llamafile v0.8.9,Testing mxbai-embed-large-v1 model,Choosing hardware for running large language models,CPU vs GPU for AI model training and inference
- Llamafile minimum hardware requirements debated: Inquiries about the minimum hardware requirements for running llama.cpp sparked a discussion on whether iPhone 13 or Raspberry Pi Zero W could manage it. Clarification revealed that a 64-bit system is needed, with specific model and memory requirements playing a crucial role.
- Community members confirmed that Raspberry Pi Zero is unsuitable due to 64-bit system requirements and noted that models' size determines the necessary memory, with some models operating on minimal RAM.
- Llamafile v0.8.9 release boasts Android support: The latest llamafile v0.8.9 release confirms working Android support and improves the Gemma2 model alignment with Google's intended usage. More progress is noted on the new embedding server.
- The community expressed appreciation for the improvements, mentioning better Gemma2 support and the potential for close alignment with Google's hosted version, which outperforms several larger models in public evaluations.
- Fix for mxbai-embed-large-v1 model issue: Users encountered an issue with the mxbai-embed-large-v1 model where all text inputs returned the same vector. Changing the input key from 'text' to 'content' resolved the issue.
- One user requested updating the Hugging Face repo to reflect this fix to prevent confusion for future users.
- Choosing optimal hardware for llamafile: Enthusiasts discussed the best hardware setups for running large language models, balancing VRAM and CPU memory. For consumer use, suggestions ranged from 3090/4090 GPUs to high-end workstation solutions like A6000/RTX 6000.
- Users shared experiences, noting the practicality of high VRAM GPUs and exploring the limits of consumer platforms in terms of memory capacity for effective model performance.
- Exploring CPU potential in model training: Discussions on CPU vs GPU capabilities highlighted the moat GPUs have over CPUs in model training due to computational demand. One example mentioned was how running large models on CPUs can be slow despite multiple cores.
- The possibility of CPU-based learning was questioned, with suggestions to test using llm.c for training GPT-2 models, underscoring the practical limits of CPUs in extensive training scenarios.
Links mentioned:
OpenInterpreter ▷ #general (25 messages🔥):
Building 01 on Windows,Docker capabilities with OI,Concurrency and resource isolation in OI deployments,Handling image displays in OI,Local AI agents for web browsing
- Building 01 on Windows Still a Challenge: piranha__ requested a guide on building 01 on Windows as the existing documentation didn't work. techfren suggested using the search function in Discord for user-shared steps.
- techfren noted that piranha__ had likely found some helpful steps in <#1194880263122075688>.
- Dockerizing Nmap Through OI: lagoonghost inquired about using Docker with OI to run tools like nmap inside a container via Jan as an interface. There wasn't any concrete answer or guide provided in response.
- No further details were provided.
- Concurrency Issues in OI Deployment: chaichaikuaile_05801 raised concerns about concurrency and resource isolation when deploying OI as a service, considering OI Multiple Instances or reassigning the context for each request. notnaton suggested that multiple instances would be best, albeit expensive.
- chaichaikuaile_05801 and notnaton discussed that resetting with
.reset()might solve code-sharing issues, but after testing, confirmed multiple instances do not share the same Python execution environment.
- chaichaikuaile_05801 and notnaton discussed that resetting with
- Displaying Images in OI: chaichaikuaile_05801 asked how to return images in OI when executing code like
MatPlotLib.show(), mentioning an open issue on GitHub. The user noted differences in functionality between versions 0.1.18 and 0.2.5.- Additionally, chaichaikuaile_05801 expressed interest in seeing enhancements to image return capabilities.
- Seeking Effective Local AI Agents: blurrybboi inquired about the availability of Local AI Agents capable of browsing the web and YouTube effectively, not just superficial searches. They are looking for AI that can perform extensive searches and filter out low-quality results.
- No responses were given regarding the current capability of such local AI agents.
Link mentioned: When I use interpreter.chat(stream=True), in what scenarios will type return 'image'? · Issue #1301 · OpenInterpreter/open-interpreter: Describe the bug When I use interpreter.chat(stream=True), in what scenarios will type return 'image'? When I try to use it in version 0.1.18, it returns image, but version 0.2.5 does not like...
OpenInterpreter ▷ #O1 (2 messages):
Portaudio installation issue on Windows 11,Pull request for updating Windows installation documentation
- Portaudio installation issue on Windows 11: A user reported an issue with installing Portaudio on Windows 11, receiving an error stating that the package can't be found.
- They later discovered a pull request updating the Windows installation documentation, which might help resolve the issue.
- Windows installation guide updated for OpenInterpreter: A pull request was found that aims to update the Windows installation documentation for OpenInterpreter.
- The update compiles learnings from previous users' attempts to install on Windows, including discussions from Zorcon on Discord.
Link mentioned: Update documentation for Windows installation by dheavy · Pull Request #203 · OpenInterpreter/01: Problem Installation for Windows, with its key differences, isn't provided in the documentation. Solution Compile learnings from previous users' attempt (including Zorcon's on Discord and ...
Torchtune ▷ #general (26 messages🔥):
Finetuning models on GPUs and logging with WandB,Training configurations and evaluation methods in torchtune,Challenges of using AMD GPUs for AI tasks,Guidance on DPO without SFT for small datasets,Converting torchtune models to HuggingFace
- Successful First Model Finetuning with Community Help: A user shared their achievement of finetuning their first model thanks to community support, mentioning they couldn't have done it on their own machine without paying for an online GPU.
- The user discussed learning the complexity of log files versus using tools like wandb for better insights, planning to run evaluations before and after following this advice.
- Switch to WandB Logging in Torchtune: A member recommended using Weights & Biases (W&B) logger instead of log files for better insights in torchtune training.
- After discussing YAML configuration issues, it was advised to remove redundant logging components to avoid errors; a simplified configuration for W&B was shared.
- Challenges with AMD GPUs for AI Tasks: A user shared their experience and a Reddit guide on using AMD GPUs for AI, recommending NVIDIA for better support despite some success with ROCm and torchtune.
- I didn't think I would ever get to finetune anything on my 6900 XT, detailing the difficulties and community assistance received in the torchtune Discord.
- DPO Training Recommendations Without SFT: A member suggested trying DPO directly on a small dataset without SFT, referencing a torchtune DPO recipe.
- Another member provided further support on dataset format and emphasized that DPO might work well without SFT for the user's specified context.
- Converting Torchtune Models to HuggingFace: A user inquired about converting torchtune models to HuggingFace and sought corresponding layer names.
- While not much detail was provided on the conversion process, it highlights the user's progress and crowning integration of tools in the AI training process.
Links mentioned:
Cohere ▷ #general (17 messages🔥):
Multi-step capabilities of the toolkit,Events and sessions at AI Engineer in San Francisco,Commad R models session by Sandra Kublik,LLM-UNIVERSITY channel sunsetting and support,Using Cohere's API and resources for development
- Toolkit enables multi-step capabilities: @meor.amer confirms that the toolkit is already enabled with multi-step capabilities, sharing an example to demonstrate this feature.
- @sssandra adds that both frontend and backend support for this is available.
- Sandra Kublik praises AI Engineer event: @sssandra shares her experience at AI Engineer in SF, complimenting the event and afterparty. She hosted a session on Commad R models, linked here.
- She mentions the inclusion of the server bots in the session. Other members agree it was a notable event.
- LLM-UNIVERSITY channel sunsetted: @.overwhelmed inquires about LLM-UNIVERSITY and its examples for integrating models.
- @xvarunx clarifies the channel has been sunsetted but support is available through other channels and instructors like @meor. Additionally, Cohere's docs and API references provide ample resources.
- Resources to get started with Cohere API: @xvarunx shares various resources like cookbooks and GitHub examples.
- He encourages users to share their projects for more support and feedback. @.overwhelmed appreciates the active support in the community.
Links mentioned:
Cohere ▷ #project-sharing (3 messages):
Cohere Slack bot creation,Performance requirements for Slack bots,Speed of model processing
- Cohere Slack Bot Eases Workspace Access: I created a Cohere Slack bot that works inside my workspace, stated one user, highlighting the integration's convenience for their team.
- Another member responded with an excited fire emoji, expressing strong approval for the quick and efficient setup.
- Slack Bots Demand Quick Responses: A user mentioned that Slack requires bots to finish requests in 3 seconds, underpinning the necessity for fast model performance.
- This showcases how speed is crucial for maintaining seamless interactions, stressing the importance of high-performing models.
Cohere ▷ #announcements (1 messages):
Cohere For AI event in London,Expedition Aya initiative,Benefits and activities of Expedition Aya,Multilingual AI research,Crew Connections meetings
- Cohere For AI Announces London Event: Cohere For AI is hosting an event in London on the evening of July 10 to celebrate and discuss multilingual AI over lightning talks, food, and drinks. This event will kick-off their latest initiative, Expedition Aya, a 6-week global challenge.
- Attendees can connect with ML researchers, gain access to exclusive resources and API credits, and receive support to launch multilingual research ideas. Special swag and exclusive prizes will be available for top projects.
- Expedition Aya: Global Open Build Challenge: Expedition Aya is a 6-week, worldwide initiative by Cohere For AI focusing on multilingual AI models Aya 23 and Aya 101. Participating teams gain access to resources, API credits, and support for launching research ideas.
- Successful teams will be eligible for limited edition swag and exclusive prizes for top projects. The initiative aims to connect researchers globally and push the boundaries of multilingual AI.
Links mentioned:
LAION ▷ #general (2 messages):
Reminder to upgrade openssh packages,Figure 1 doing full end-to-end BMW use cases with pixel-to-action neural networks
- Reminder: Upgrade your OpenSSH packages: A member reminded everyone to upgrade their OpenSSH packages if they run any internet-connected servers.
- No further details or links were provided in the message.
- Figure 1 achieves precise BMW use cases: Corey Lynch announced that Figure 1 is now doing full end-to-end BMW use cases with all manipulations learned as 200hz pixel-to-action neural networks.
- Learned behaviors need to be incredibly precise (<1cm sheet metal insertion) and work over a long horizon.
Link mentioned: Tweet from Corey Lynch (@coreylynch): Figure 1 is now doing full end-to-end BMW use cases, with all manipulations learned as 200hz pixel-to-action neural networks. Learned behaviors need to be incredibly precise (<1cm sheet metal ins...
LAION ▷ #research (15 messages🔥):
ML model evaluation complexity,Novel LLM: phi-CTNL,Correct solution validation for AIW+ problem,Clarification on problem-solving assumptions,Introduction of new model architecture: Terminator
- Evaluating Finetuned Models is Painful: In my last post, a user outlined the complexities and pain points of evaluating finetuned LLMs for structured data extraction from press releases, highlighting the core metric, accuracy, and other evaluation metrics.
- They emphasized the hidden code and slowness of the process, noting that, without a proper system, the complexity of maintaining the evaluations mounts up.
- phi-CTNL Outperforms All Known Models: The abstract of a recent paper introduces phi-CTNL, a 1 million parameter transformer-based LLM pretrained on a novel, curated dataset mixture.
- This model achieves perfect results across diverse academic benchmarks and exhibits an unprecedented grokking-like ability to predict evaluation benchmarks' canaries.
- Correct AIW+ Solutions Verified: A user suggested that a correct solution to the AIW+ problem has been verified by others and is backed by stronger models.
- They advised using a diagram of all relations for a formal checked solution and provided a rare correct response example from Claude 3 Opus, validating the answer.
- Clarifying Assumptions in Problem Statements: Users discussed assumptions in problem statements, particularly in the AIW+ problem related to the number of Alice's siblings and cousins.
- One user questioned the reasoning that led to the conclusion, arguing that Alice could have brothers, thereby affecting the problem's solution.
- New Model Architecture: Terminator: @LeopolisDream introduced the new architecture called 'Terminator,' which features no residuals, no dot product attention, and no normalization.
- They provided a link to the paper for further details on the architecture.
Links mentioned:
LLM Finetuning (Hamel + Dan) ▷ #general (7 messages):
Knowledge graphs and Lang Graph in AI projects,Voice detection and transcription models,Recording of latest talks,Lessons from a year of building with LLMs
- Streamlining Audio Processing with Chainlit Cookbook: A member discussed implementing a voice detection model using SileroVAD and transcription with whisper-fast, enhancing it with minor preprocessing and a fast TTS-API. They recommended a Chainlit cookbook example for a quick test.
- The community also mentioned using elevenlabs (turbo), playht, or deepgram for TTS solutions, streamlining the workflow for efficient audio processing.
- Inquiry about Knowledge Graphs: A community member asked another about their work with knowledge graphs and Lang Graph in AI projects. The question aimed to dive deeper into experiences shared previously.
- This sparked interest among other members, reflecting the community's focus on leveraging graph technologies for advanced AI applications.
- Recording Availability for Recent Talks: When asked about the availability of recordings for the latest talks, a member confirmed that <@916924724003627018> was responsible for uploading the recordings.
- The discussion clarified that the 'last talk' referred to **
Link mentioned: cookbook/audio-assistant at main · Chainlit/cookbook: Chainlit's cookbook repo. Contribute to Chainlit/cookbook development by creating an account on GitHub.
LLM Finetuning (Hamel + Dan) ▷ #🟩-modal (1 messages):
Processing large datasets from Kaggle competitions,Using Dask for data processing,Out of Memory (OOM) errors in Dask,Executing Dask jobs on Modal
- Dask trips on USPTO Kaggle dataset size: A community member described efforts to process a large dataset from the USPTO competition on Kaggle, running into OOM errors while joining data using Dask.
- He sought advice on executing Dask jobs on Modal, sparking discussion on the best practices for handling large datasets.
- Modal for seamless Dask executions?: The user inquired whether anyone had successfully executed Dask jobs on Modal to mitigate memory issues.
- This query highlighted the potential of Modal in handling computational tasks more efficiently, and prompted others to share their experiences or alternatives.
LLM Finetuning (Hamel + Dan) ▷ #paige_when_finetune (1 messages):
shamik_53759: Yep, it's up now. Thanks!
LLM Finetuning (Hamel + Dan) ▷ #axolotl (2 messages):
Autotrainer suggestion,Clarification on Autotrainer
- Autotrainer Suggestion Raised: A member suggested trying autotrainer with the phrase, 'Maybe try autotrainer?'.
- Inquiries followed about whether autotrainer is an axolotl feature or related to Huggingface autotrain, highlighting some uncertainty among participants.
- Clarification Sought on Autotrainer: Another member asked for clarification on autotrainer, questioning if it is an axolotl feature or a part of Huggingface autotrain.
- A response indicated unfamiliarity with the term, suggesting it might be related to Huggingface autotrain after looking it up.
LLM Finetuning (Hamel + Dan) ▷ #openai (1 messages):
OpenAI credit consumption feedback
- OpenAI pricing guilt: A member stated that OpenAI's pricing is so affordable that they feel guilty for not being able to use their $500 credits within the next 3 months.
- They expressed this sentiment humorously with an upside-down face emoji (🙃), highlighting the perceived value of OpenAI's offerings.
- Affordable AI services draw mixed emotions: The affordability of OpenAI's credits prompts feelings of guilt in some users for not being able to fully utilize their allocated $500 credits before expiration.
- One user humorously remarked about this situation with an upside-down face emoji, signaling a lighthearted take on the dilemma.
LLM Finetuning (Hamel + Dan) ▷ #bergum_rag (4 messages):
Location of slide deck in the video,Jo's slide deck request
- Confusion over slide deck location: Remi1054 asked if the slide deck mentioned in a video had been shared, stating they may have missed its location.
- Another member jt37 clarified that decks are usually on Maven but acknowledged it was not there.
- Jo's slide deck inquiry: Another piece of clarification came when hamelh mentioned that not everyone shares their decks but he was able to ask Jo for his slide deck.
- This seems to be a specific case where Jo had to be directly approached to share his slide deck.
AI Stack Devs (Yoko Li) ▷ #app-showcase (1 messages):
mikhail_ee: Some fresh locations from https://Hexagen.World
AI Stack Devs (Yoko Li) ▷ #ai-town-discuss (5 messages):
Request for Docker port,PR for Docker port suggested,GitHub page for AI Town setup on Windows using WSL shared
- Request for Docker port in AI Town: A member mentioned that a Docker port would be fantastic for AI Town. They expressed a desire for this feature to be implemented.
- "Sounds like it would be great in the README. Can you submit a PR?" another member responded, encouraging the submission of a PR.
- GitHub page for AI Town setup on Windows using WSL: A member shared a GitHub page detailing the setup of AI Town on Windows using WSL. The page provides a comprehensive guide for setting up the development environment.
- One member highlighted the necessity for this guide to be included in the main repo and reiterated the long-standing need for a Docker image for AI Town.
Link mentioned: GitHub - Ikkitsuna/AI-Town-Windows-Setup-WSL-method: Guide for setting up AI Town on Windows using WSL: Guide for setting up AI Town on Windows using WSL. Contribute to Ikkitsuna/AI-Town-Windows-Setup-WSL-method development by creating an account on GitHub.
Interconnects (Nathan Lambert) ▷ #news (5 messages):
Apple's observer seat at OpenAI,Phil Schiller joining OpenAI board as observer,Microsoft's investment vs. Apple's exposure deal,Reactions to Apple's deal with OpenAI,Comparisons between Apple's and Microsoft's deals with OpenAI
- Apple secures observer seat at OpenAI: Apple will get a board observer seat at OpenAI later this year as part of its partnership for Apple Intelligence. Phil Schiller, head of the App Store and former marketing chief, will be taking the seat source.
- Community humorously notes that while Microsoft invested billions in OpenAI, Apple secured significant advantages with minimal investment, highlighting the genius of Tim Cook.
- Microsoft vs. Apple OpenAI deals: Discussions arose around the disparity between Microsoft's billion-dollar investment in OpenAI and Apple's less financially intensive yet effective deal. Apple's partnership resulted in a great app and significant iPhone integration, leading to humorous comparisons source.
- Members commented on how Microsoft is getting bullied in the deal, expressing amusement at the situation.
Links mentioned:
Datasette - LLM (@SimonW) ▷ #ai (2 messages):
Discussion on the evolution of internet browsing on mobile phones.,American federal officials receiving foreign gifts.,Historical context of early mobile internet services.,Foreign gifts as data and their recording issues.
- Most AI products making a familiar mistake: An article on dbreunig.com discusses how early mobile internet services, like WAP, were limited and underutilized, drawing a parallel to current AI product mistakes. The author describes the pre-iPhone era's attempts to optimize mobile browsing for wider user adoption.
- The article emphasizes that modern AI products should focus on improving user experience rather than merely adapting to smaller platforms. “Content was like reading the internet by peering through a keyhole.”
- Foreign gifts to U.S. officials analyzed: A Scoop article details how American federal officials often receive unusual and costly gifts from foreign governments. Examples include crocodile insurance and gold medallions.
- The piece highlights the challenges in how these gifts are recorded and accessed, often being stored in unstructured formats like PDFs. This underscores a broader issue of government data handling. “These foreign gifts really are data.”
Links mentioned:
{% else %}
The full channel by channel breakdowns have been truncated for email.
If you want the full breakdown, please visit the web version of this email: [{{ email.subject }}]({{ email_url }})!
If you enjoyed AInews, please share with a friend! Thanks in advance!
{% endif %}